Classement

Contenu populaire
Contenu avec la plus haute réputation dans 03/04/2026 Dans tous les contenus
-
Bonjour, Oui le dossier Tenlog est assez important en ressources !! Pour répondre au sujet du BED oui le fait d'ajouter un plateau PEI améliore la géométrie du plan d'impression (c'est ce que j'ai sur ma tenlog TLD3) le montage est facile L'écran DWIN à toujours présenté des défauts de fonctionnement erratiques (pannes d'affichage et autres défaut) Je vous propose de le changer par un écran TJC de meilleure qualité ( pour les driver carte mère ou LCD tout est dans le forum) Concernant les brosses de nettoyages pour les extrudeurs c'est une bonne solution efficace le lien de téléchargement Firmware carte mère et écrans Il est possible en premier temps de mettre à jour le firmware de l'écran DWIN (attention il y a deux modèles bien utiliser le bon firmware selon la référence de l'écran LCD) mais je doute je pense à un problème thermique du CPU!!! A+ Francis1 point
-
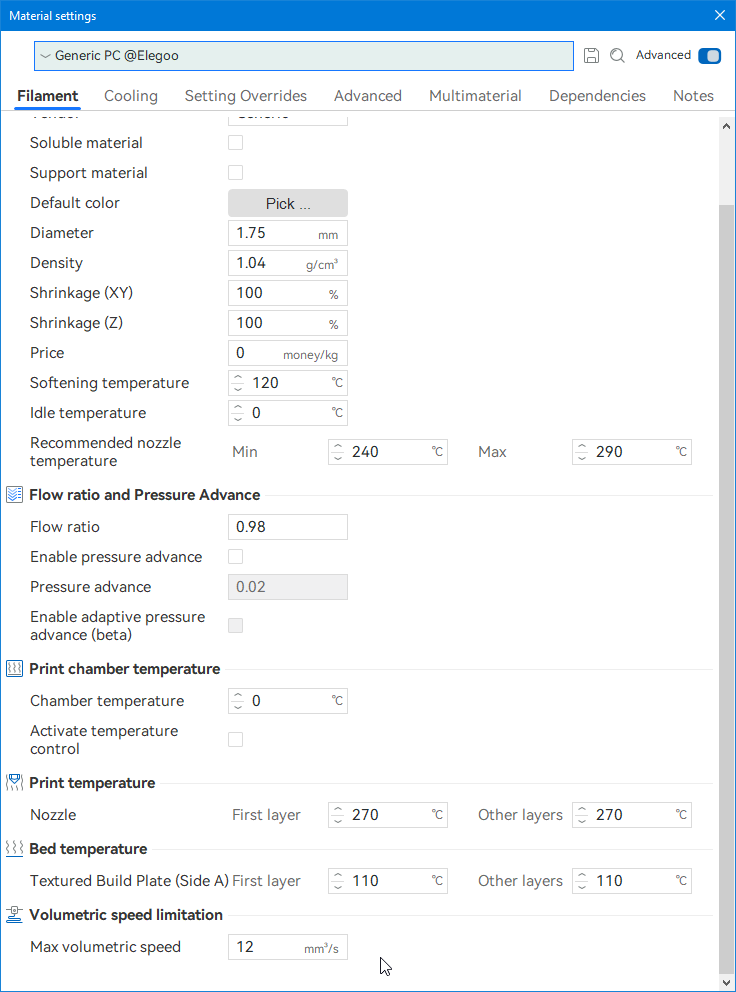
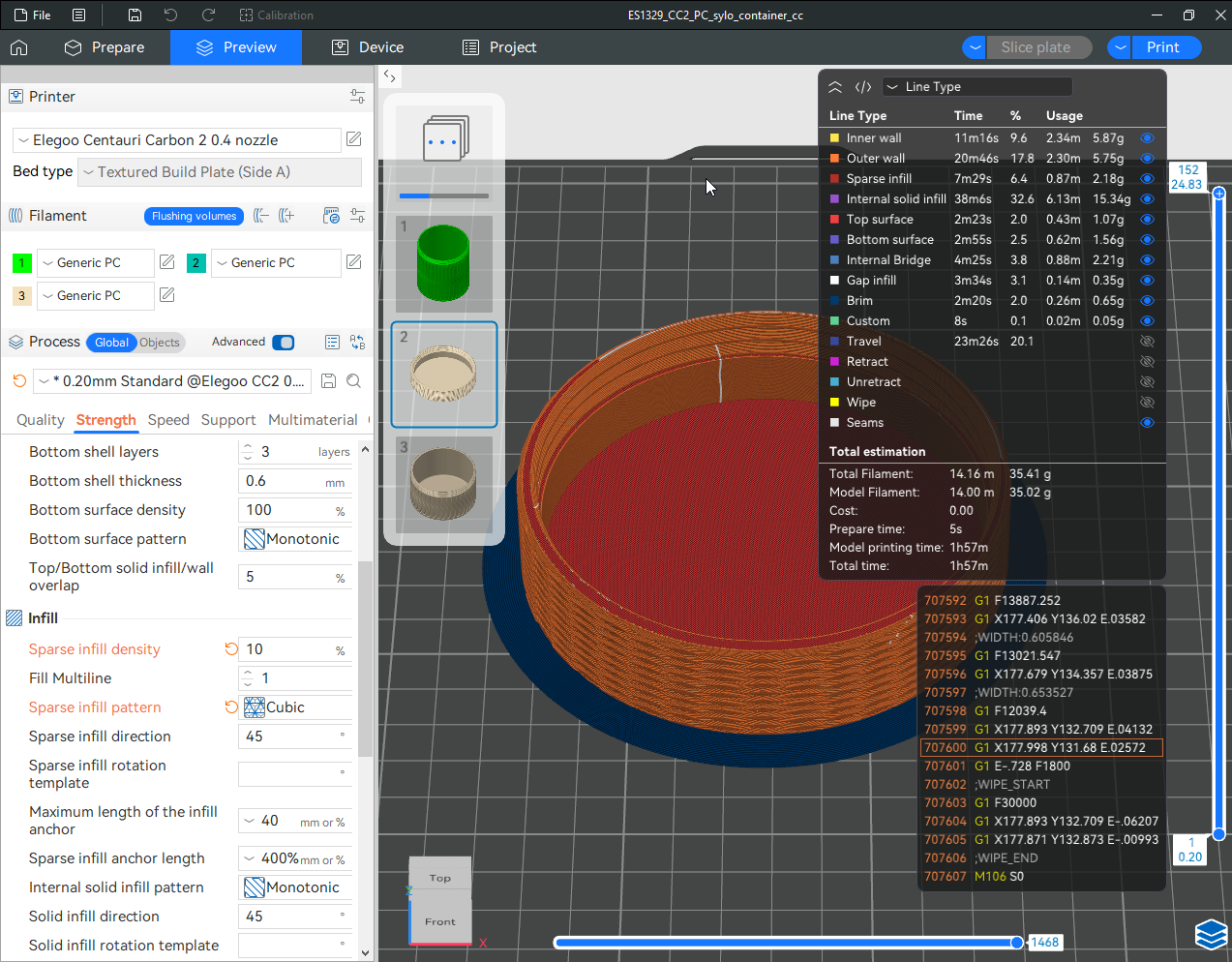
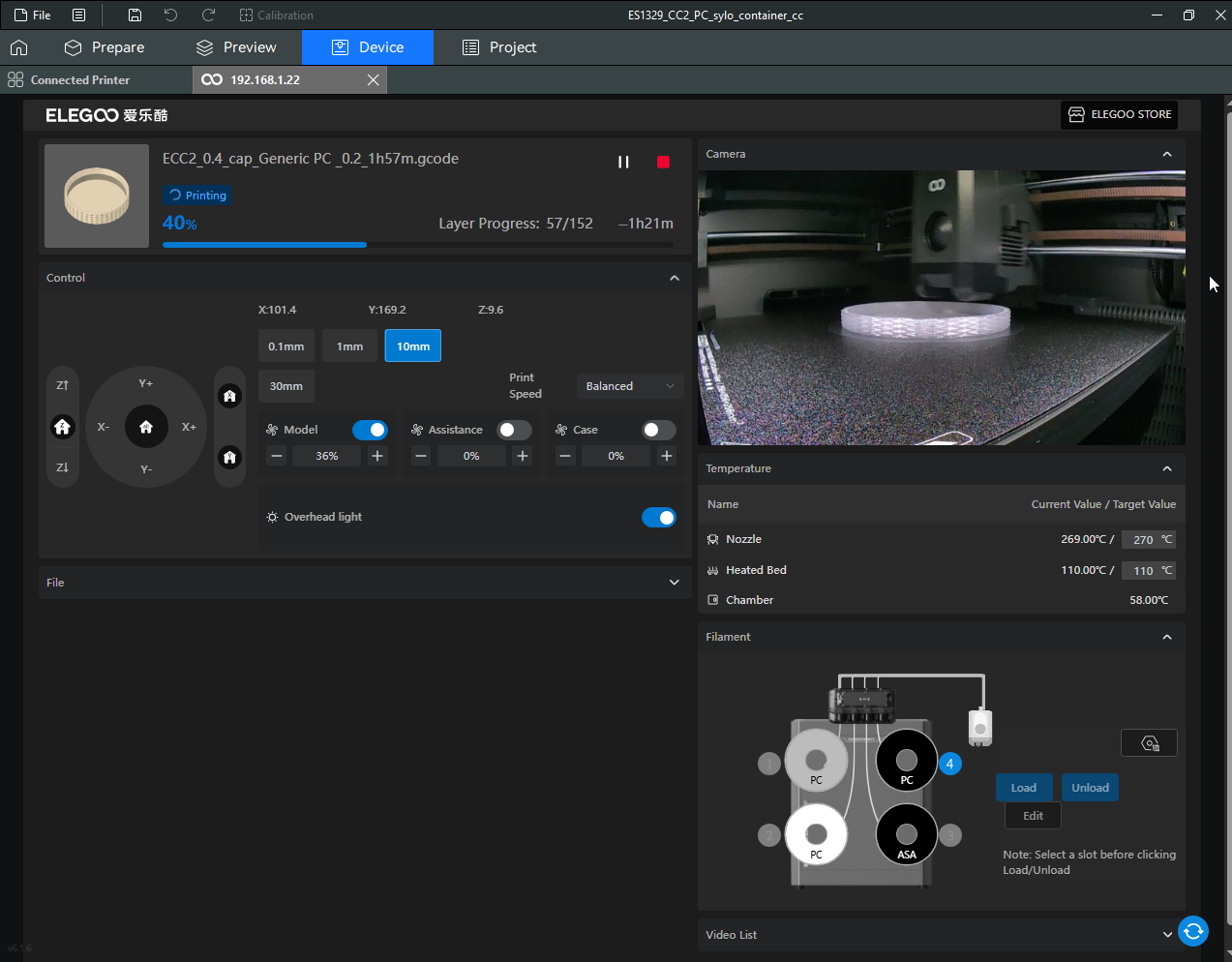
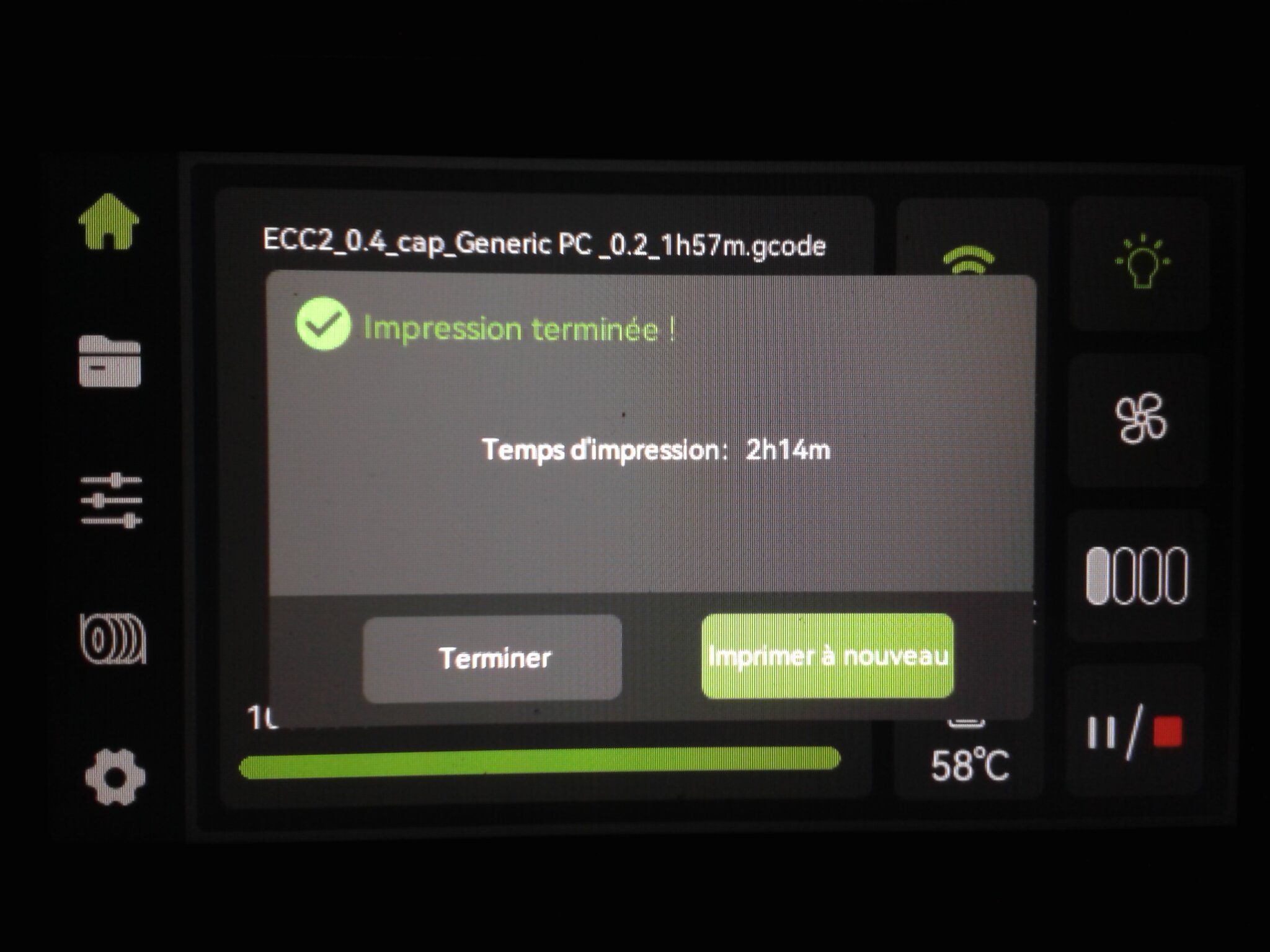
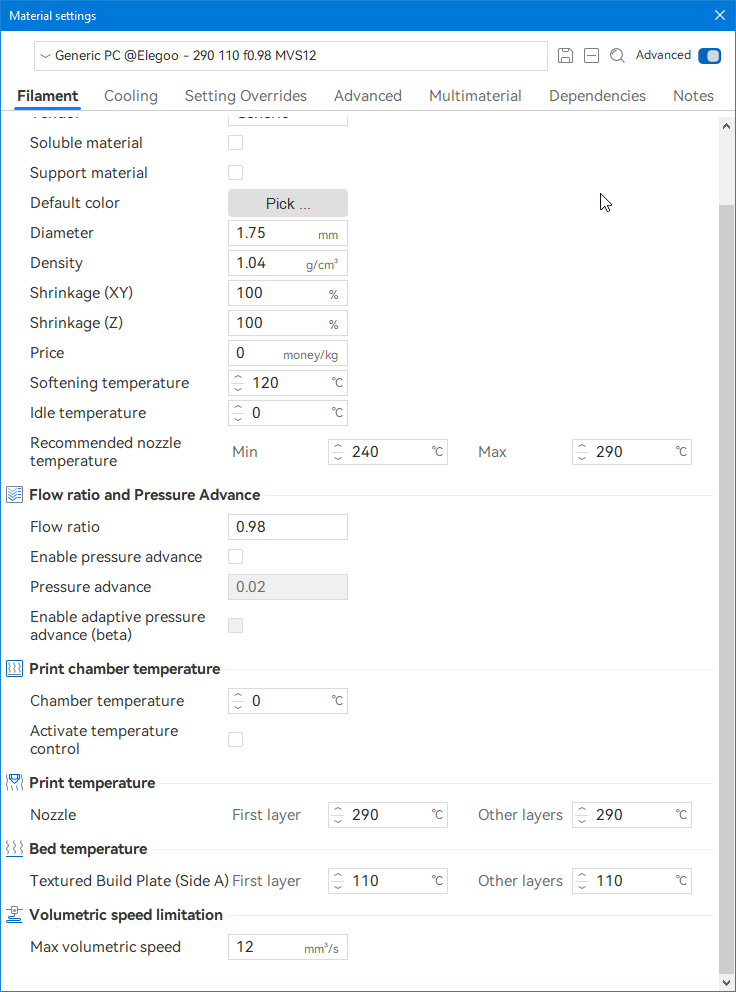
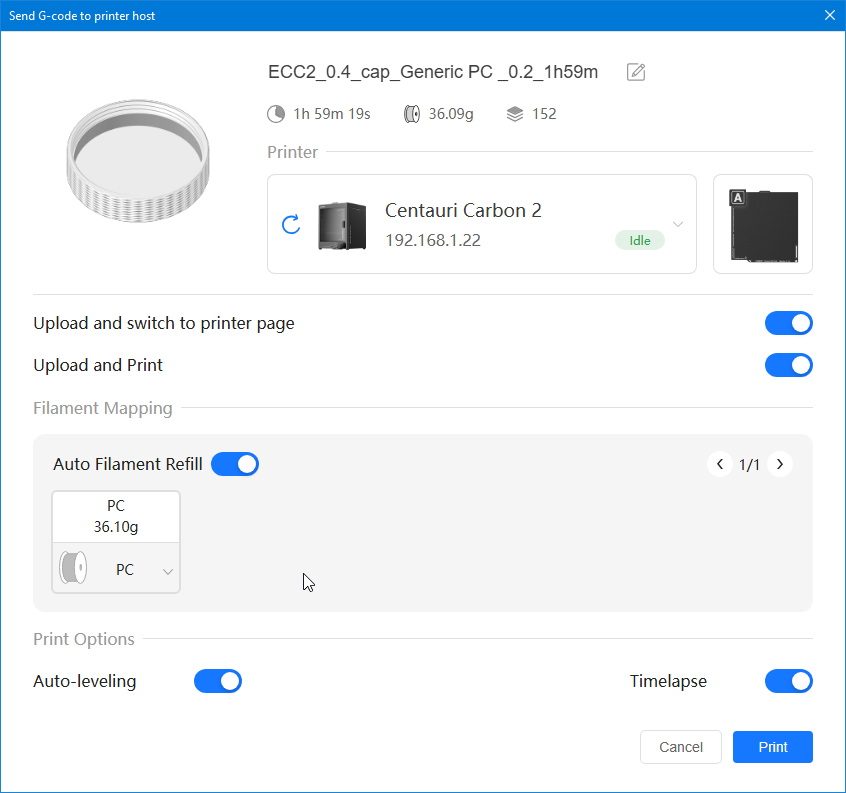
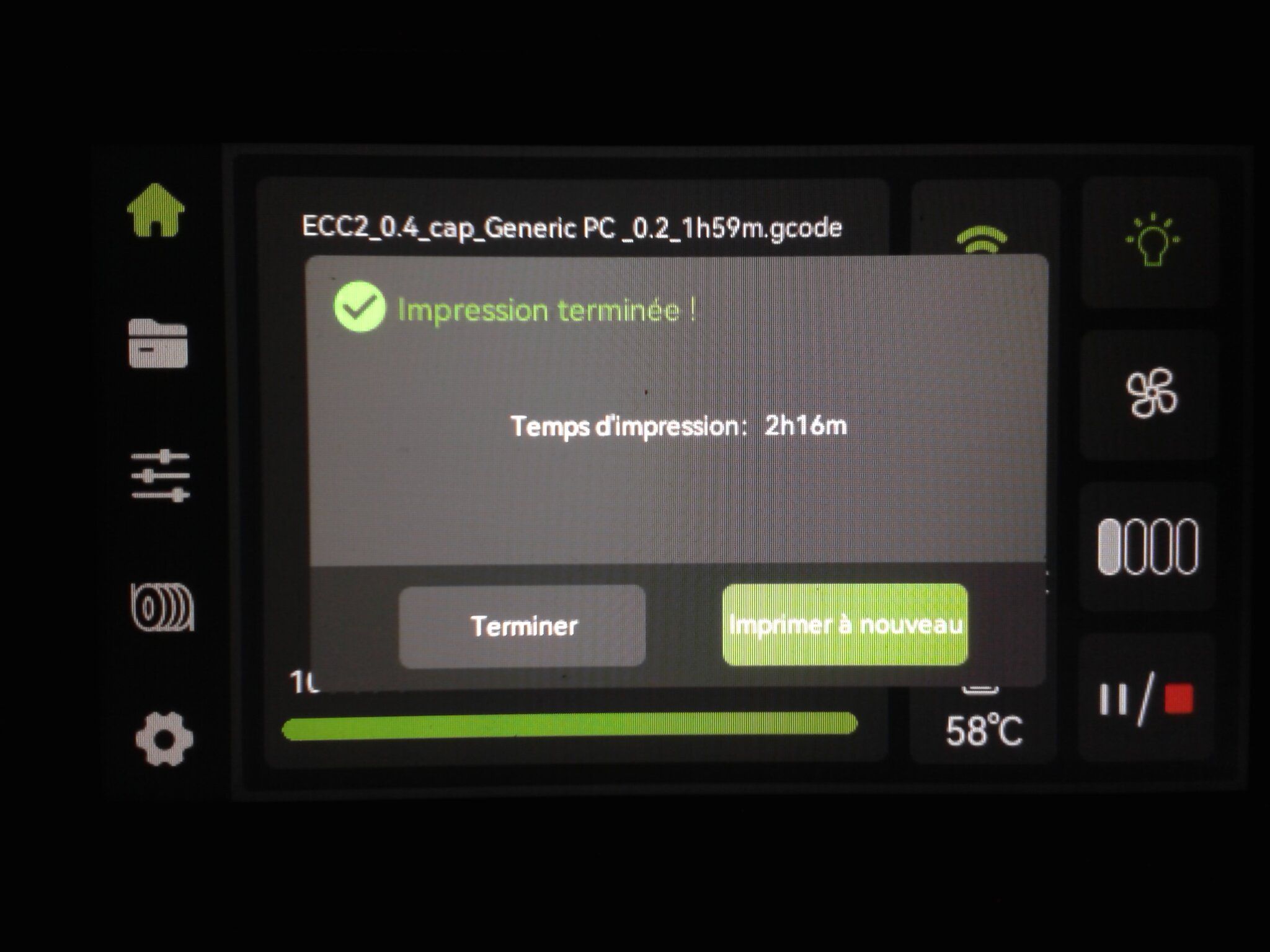
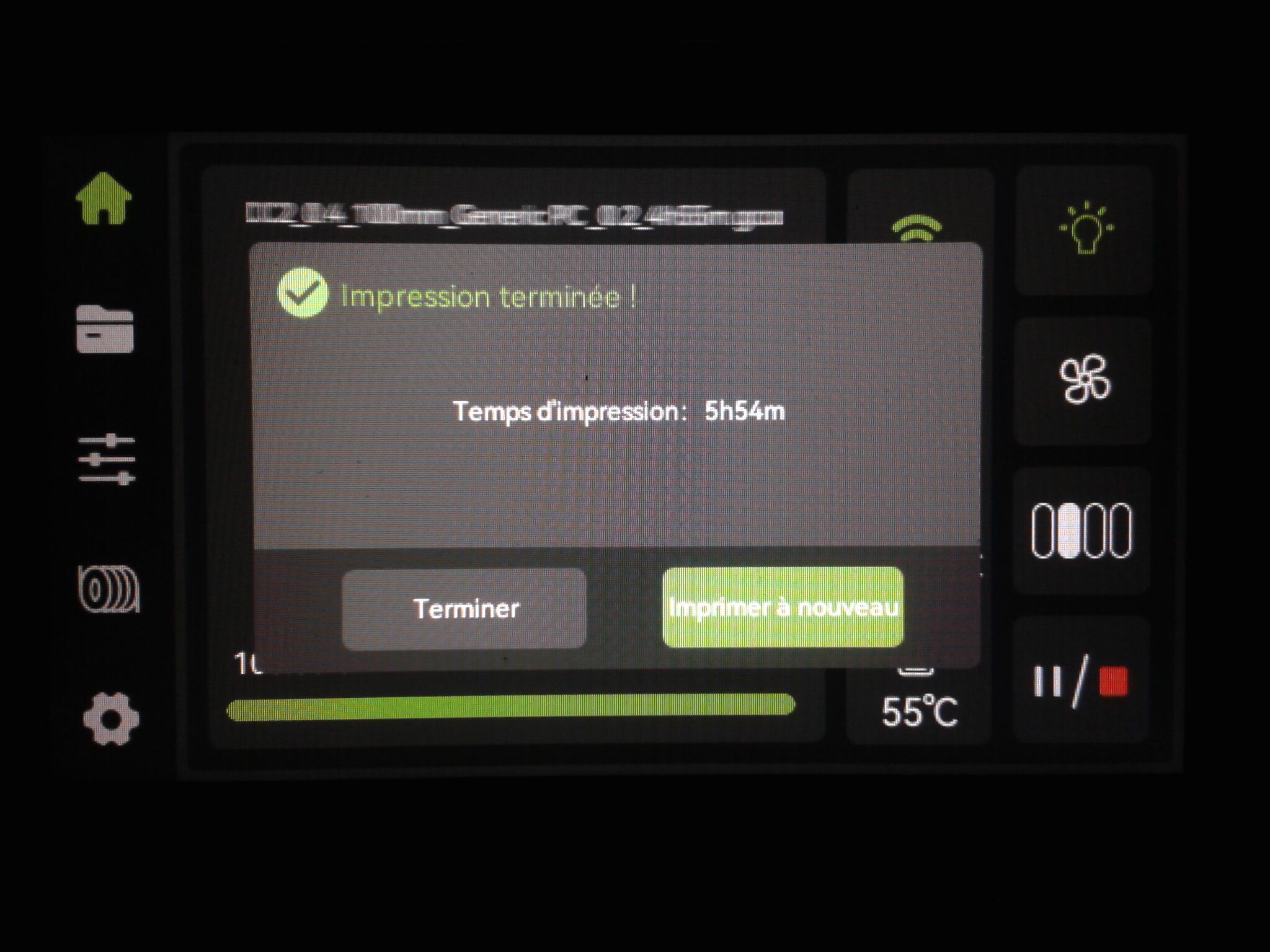
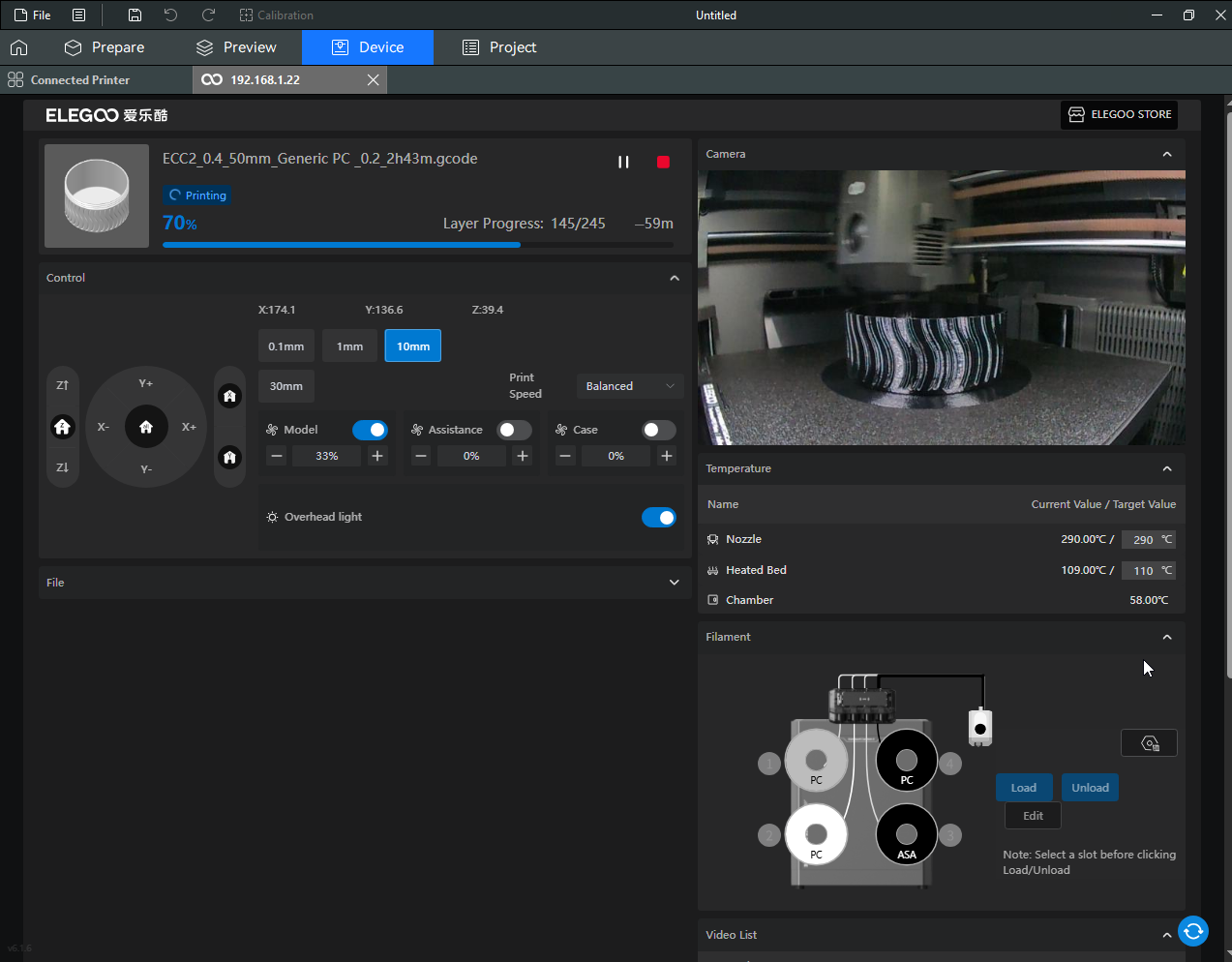
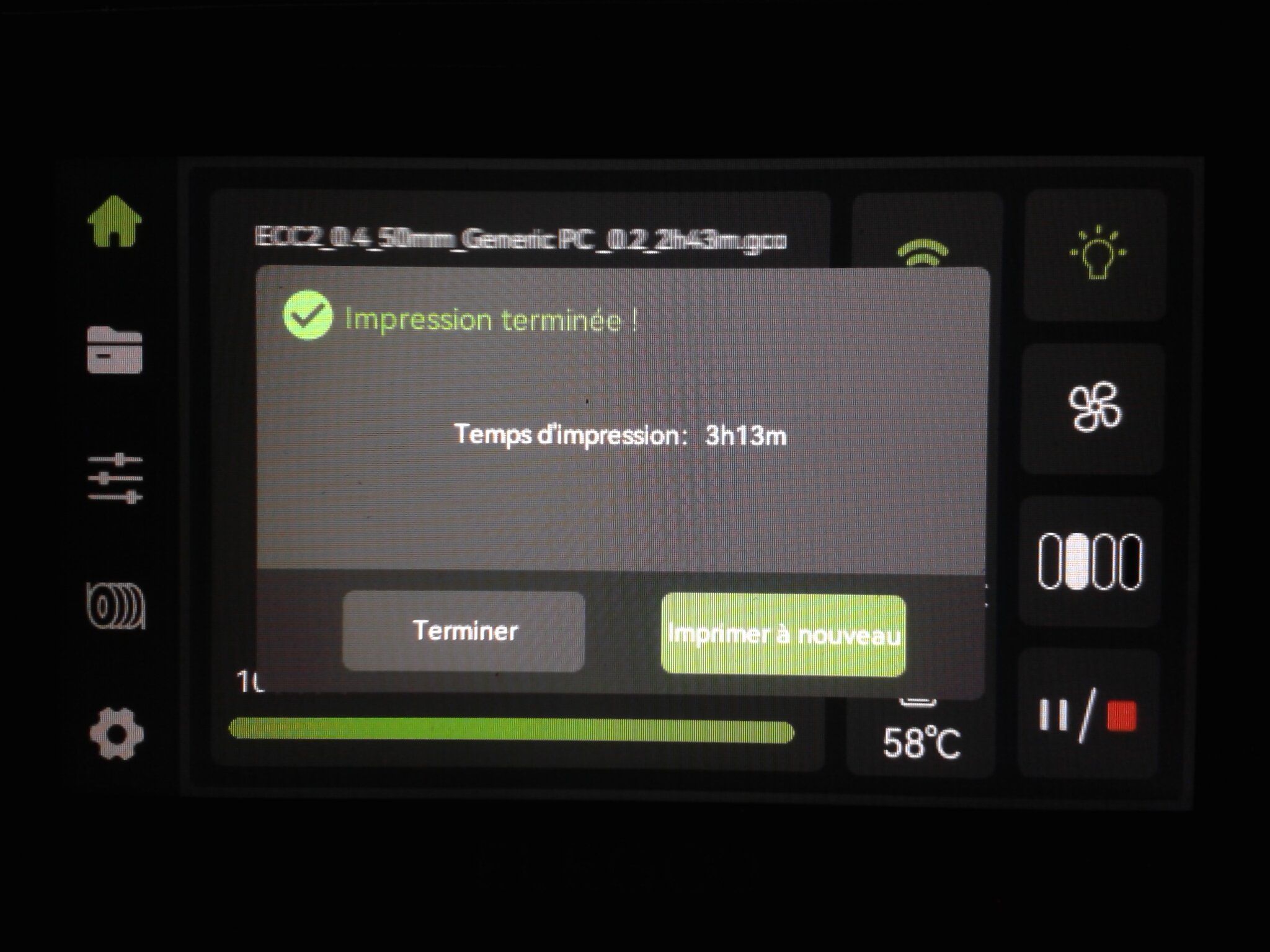
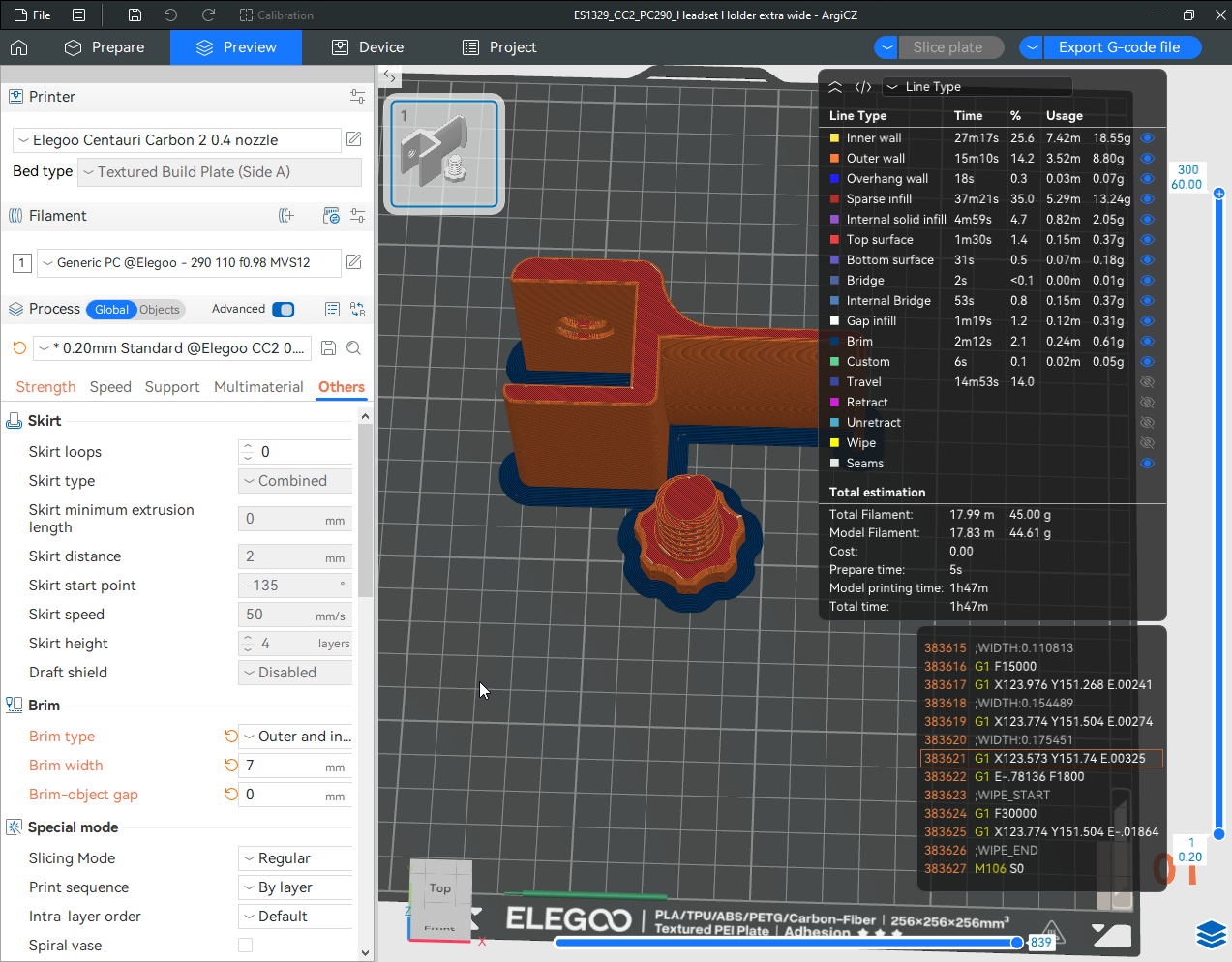
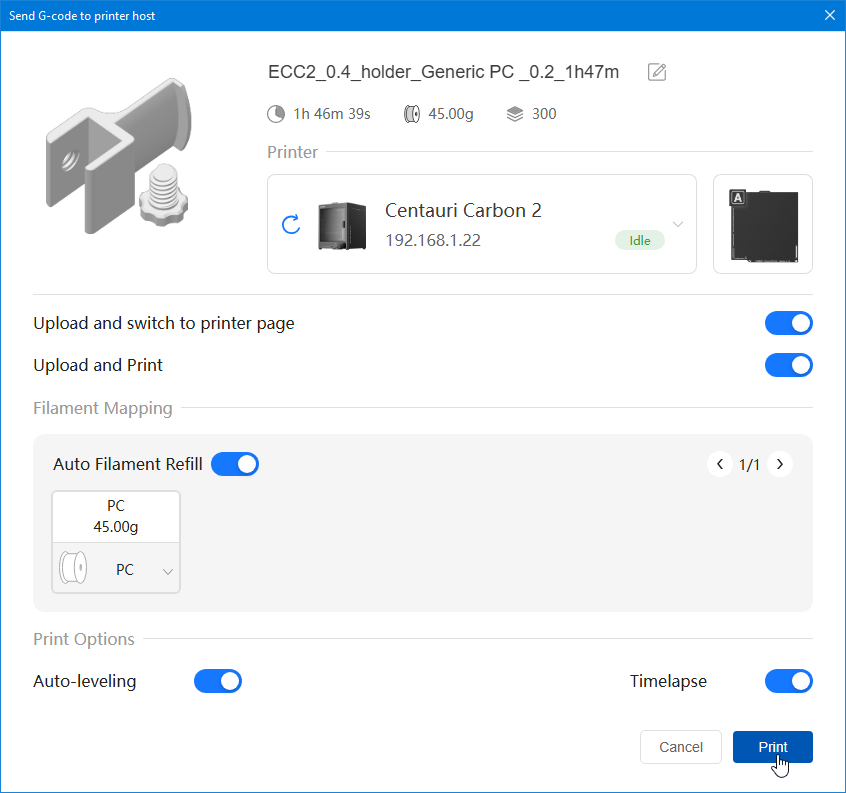
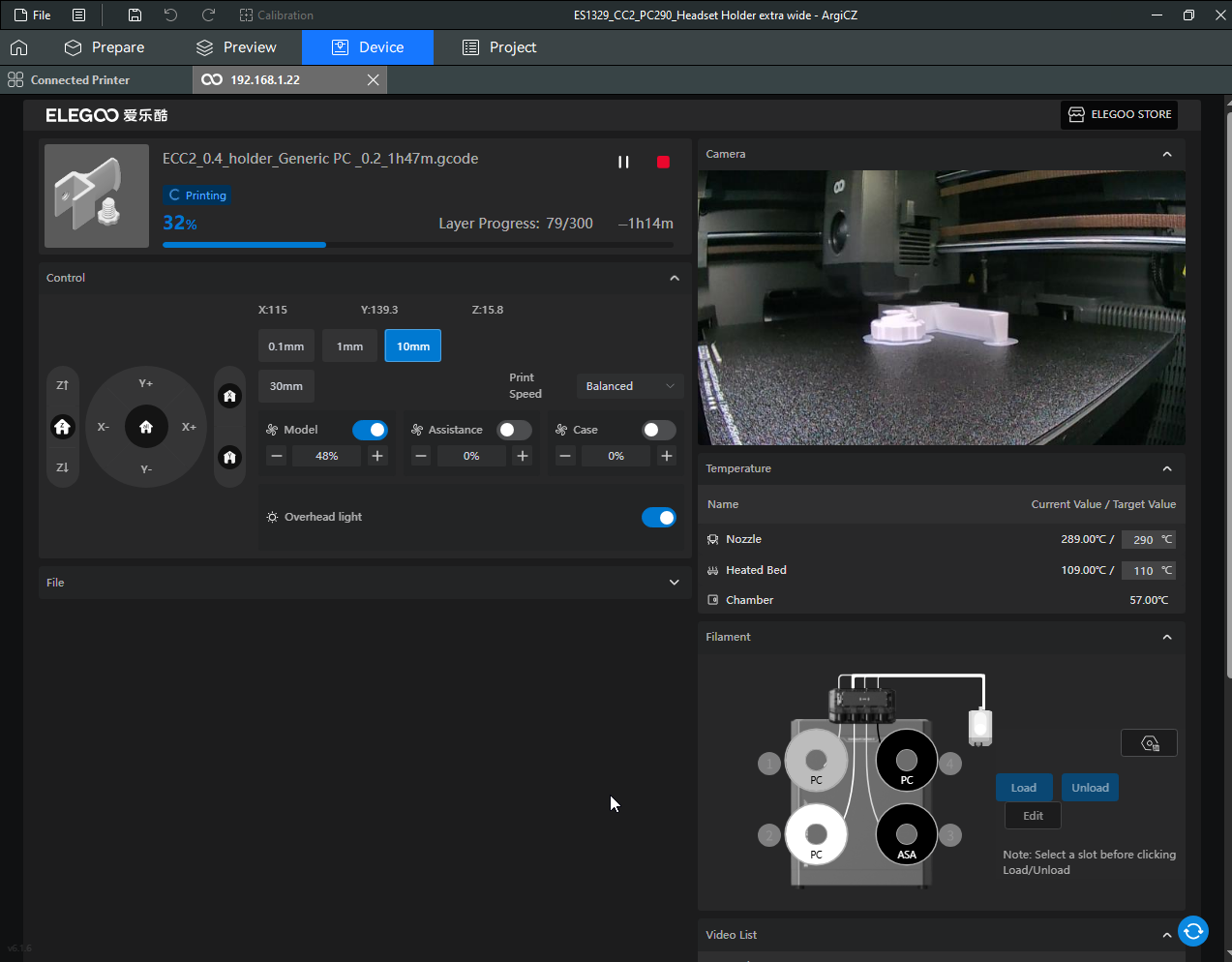
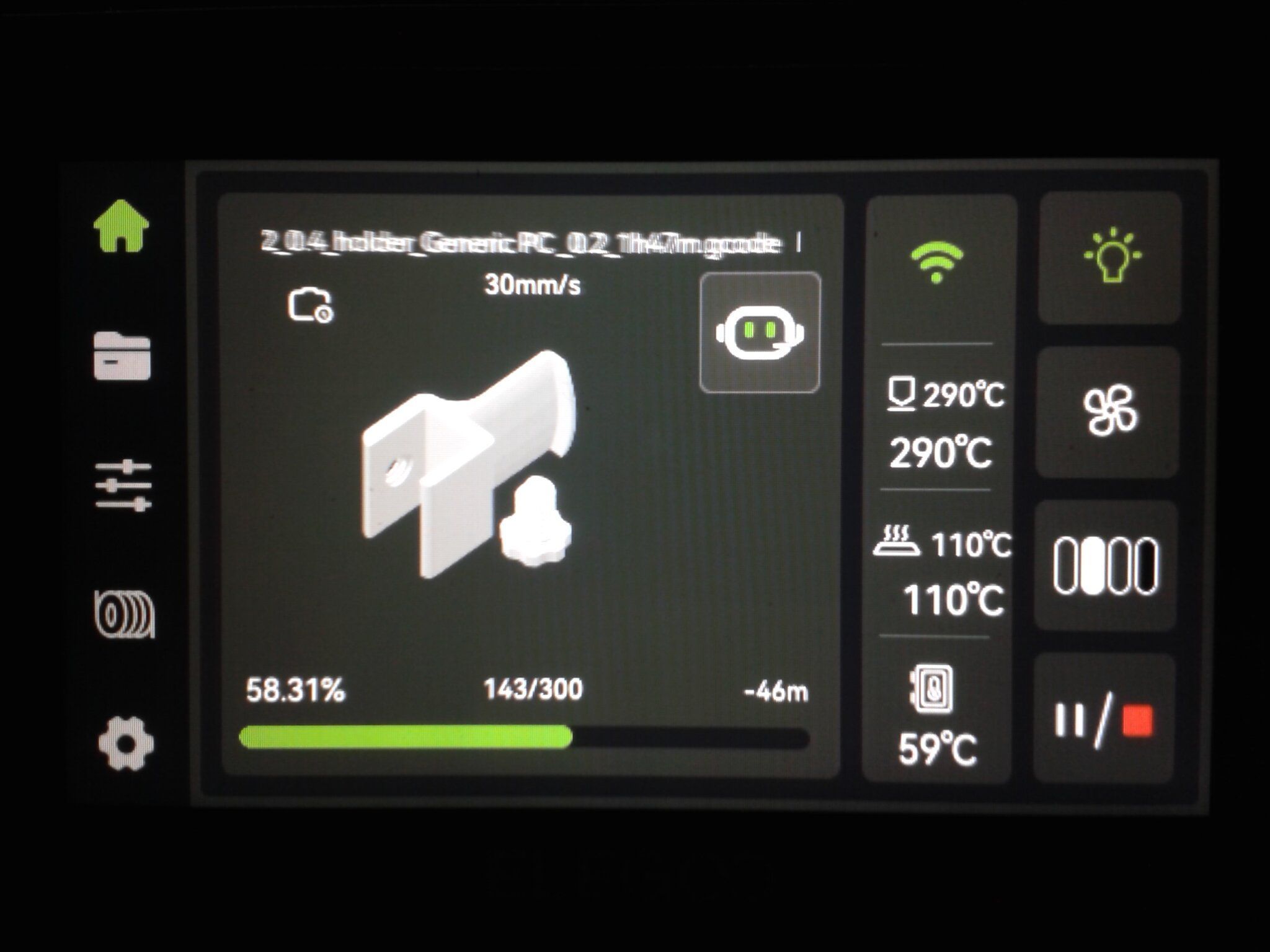
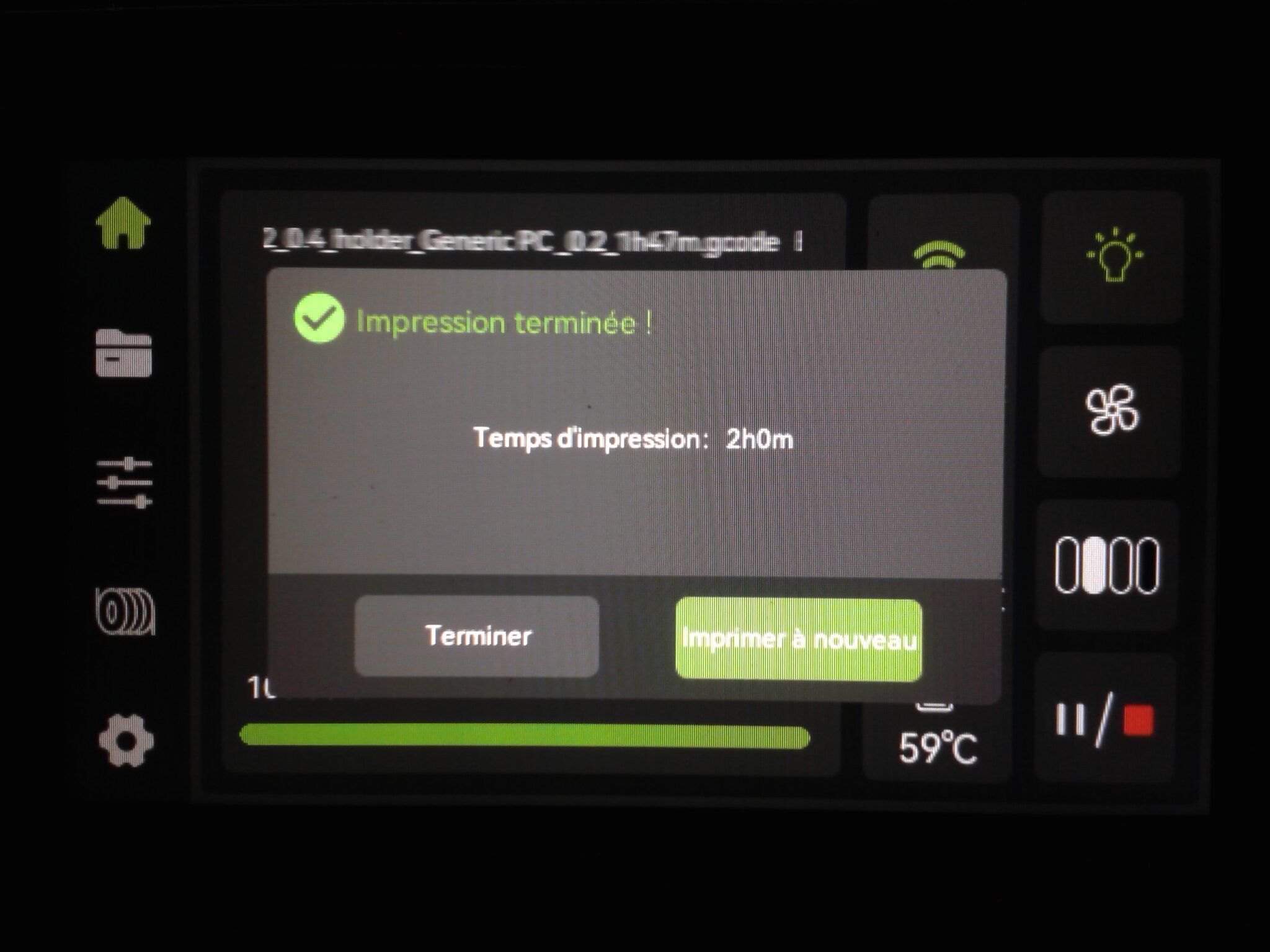
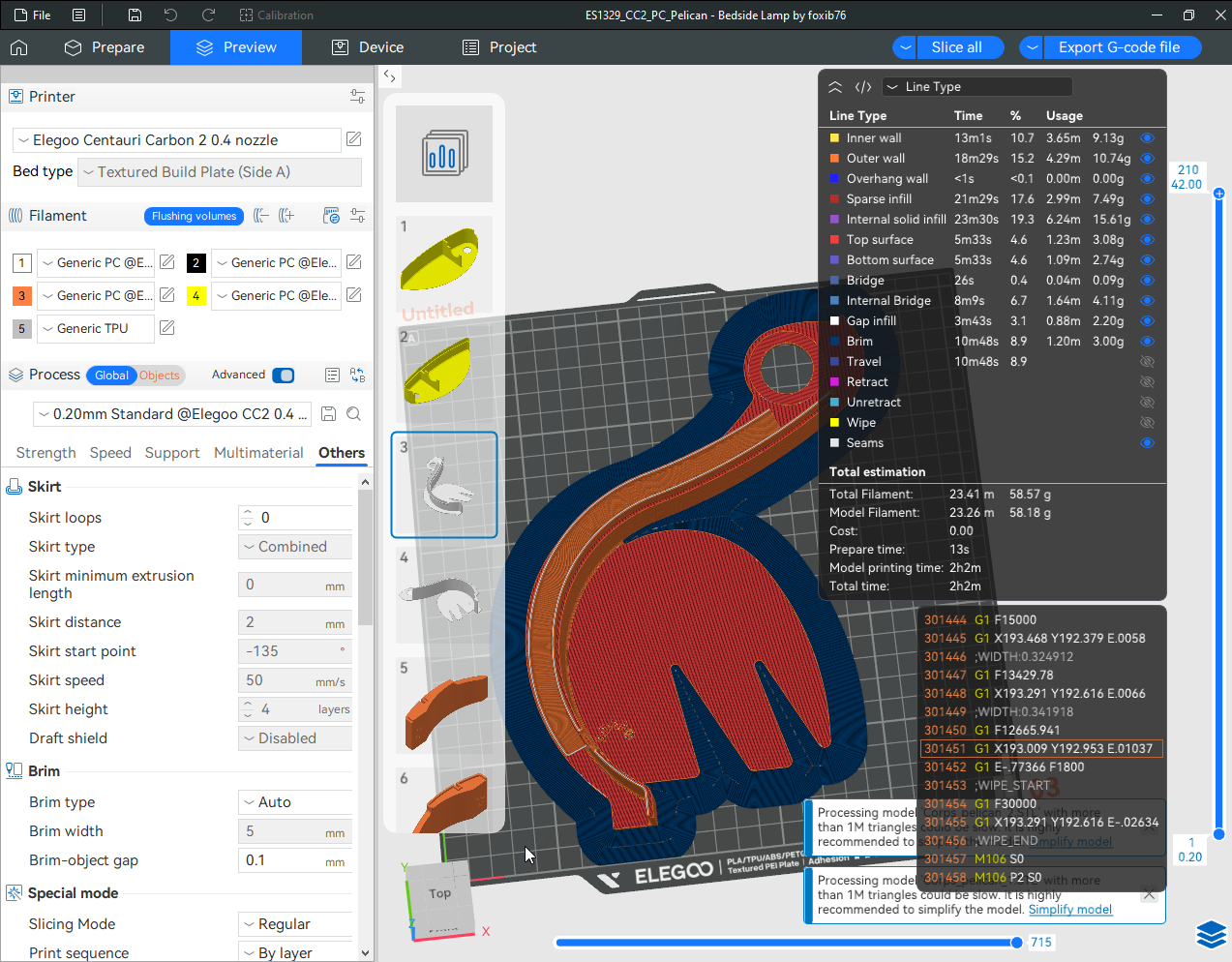
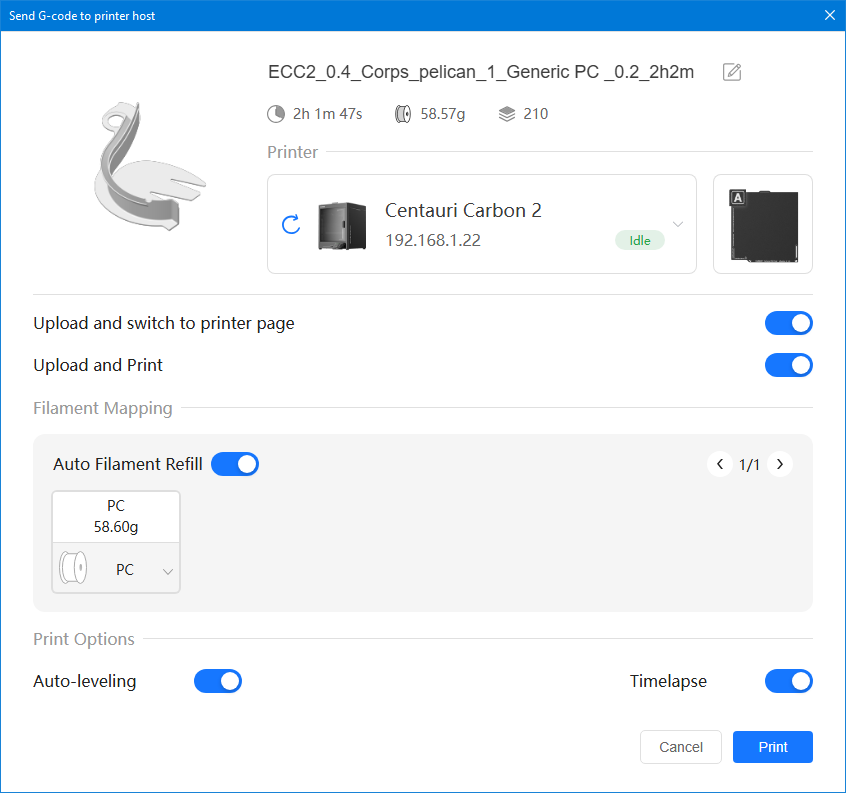
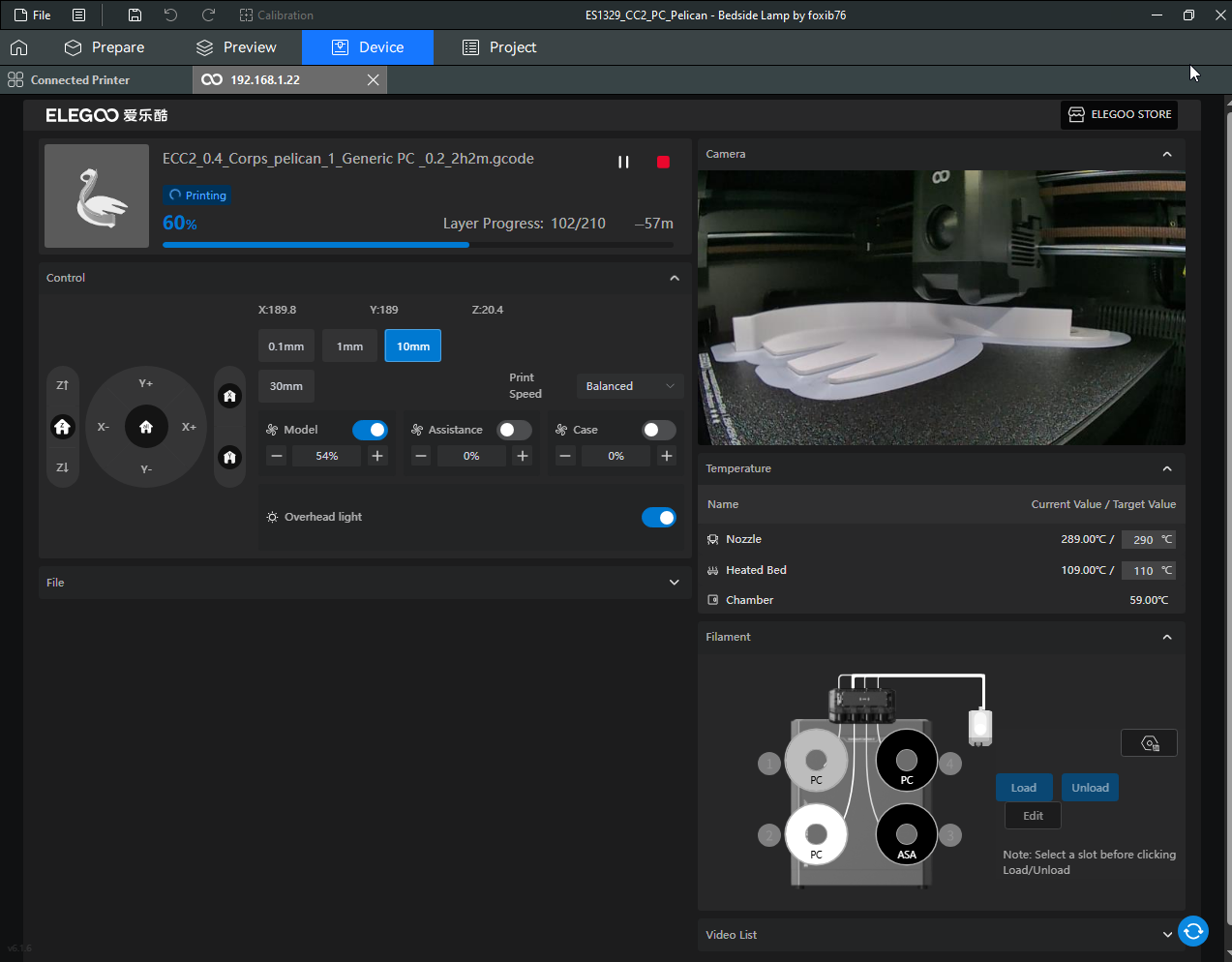
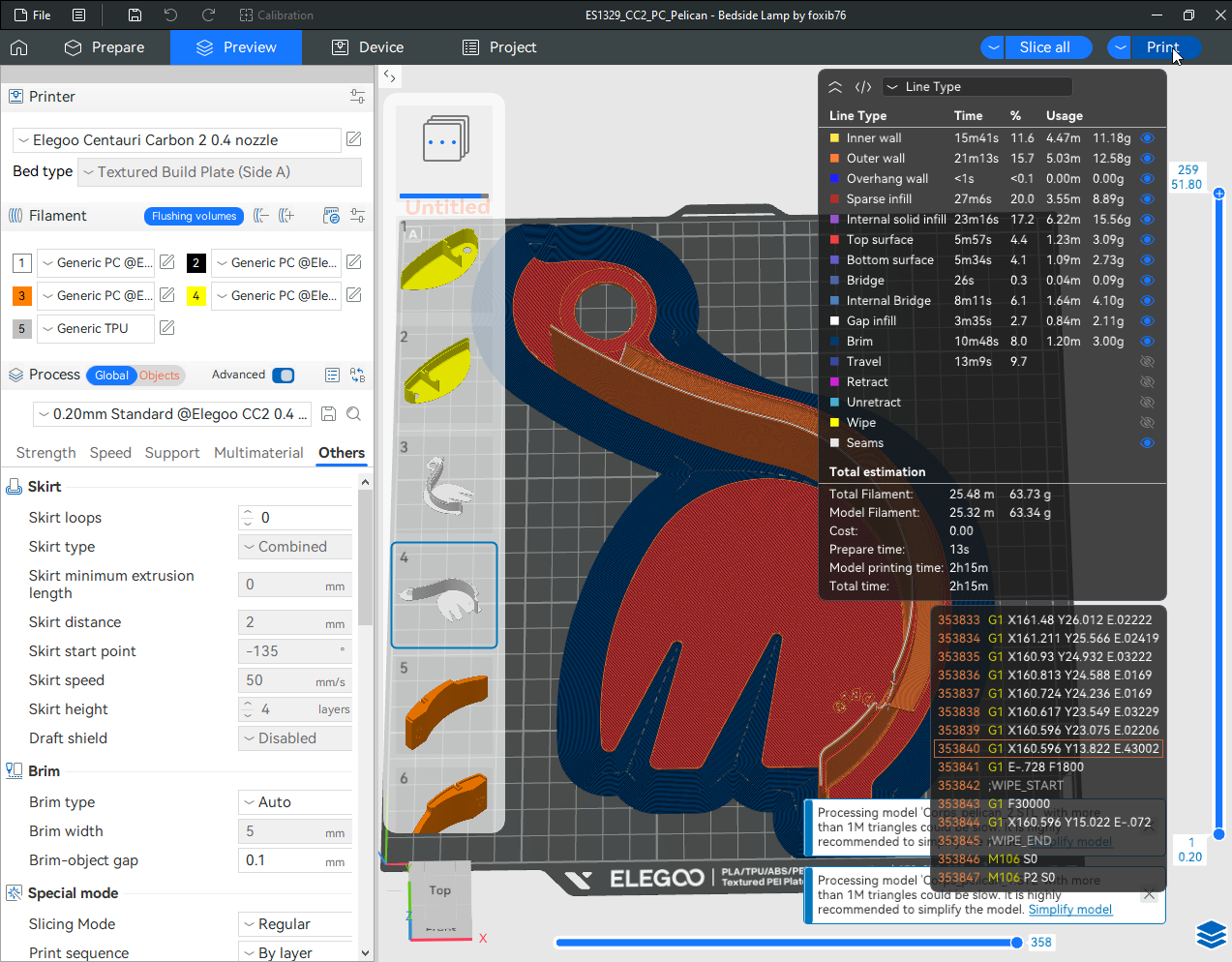
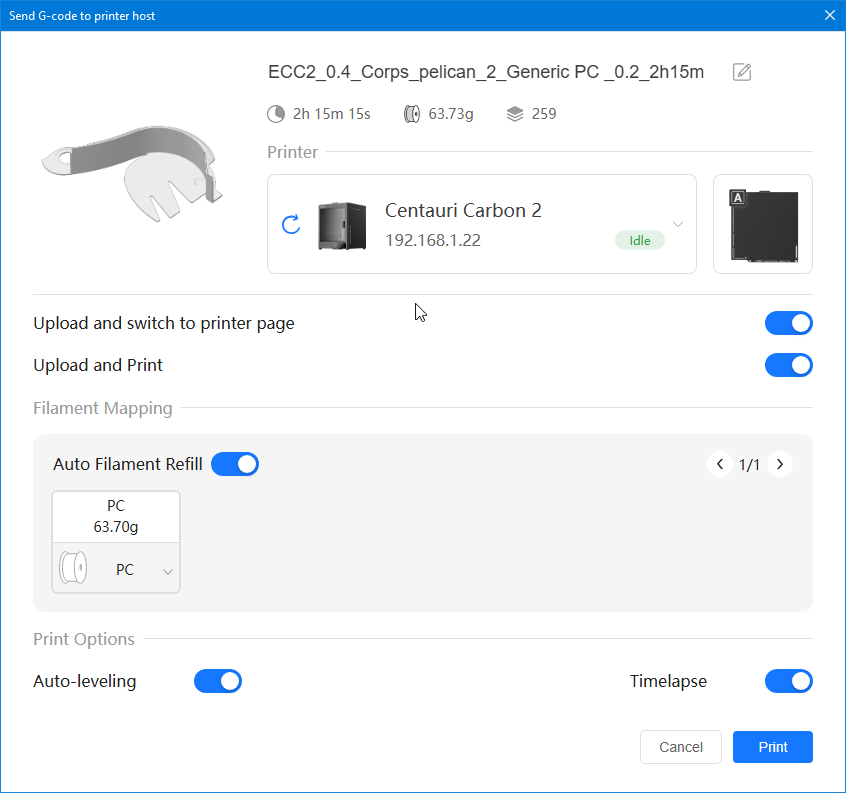
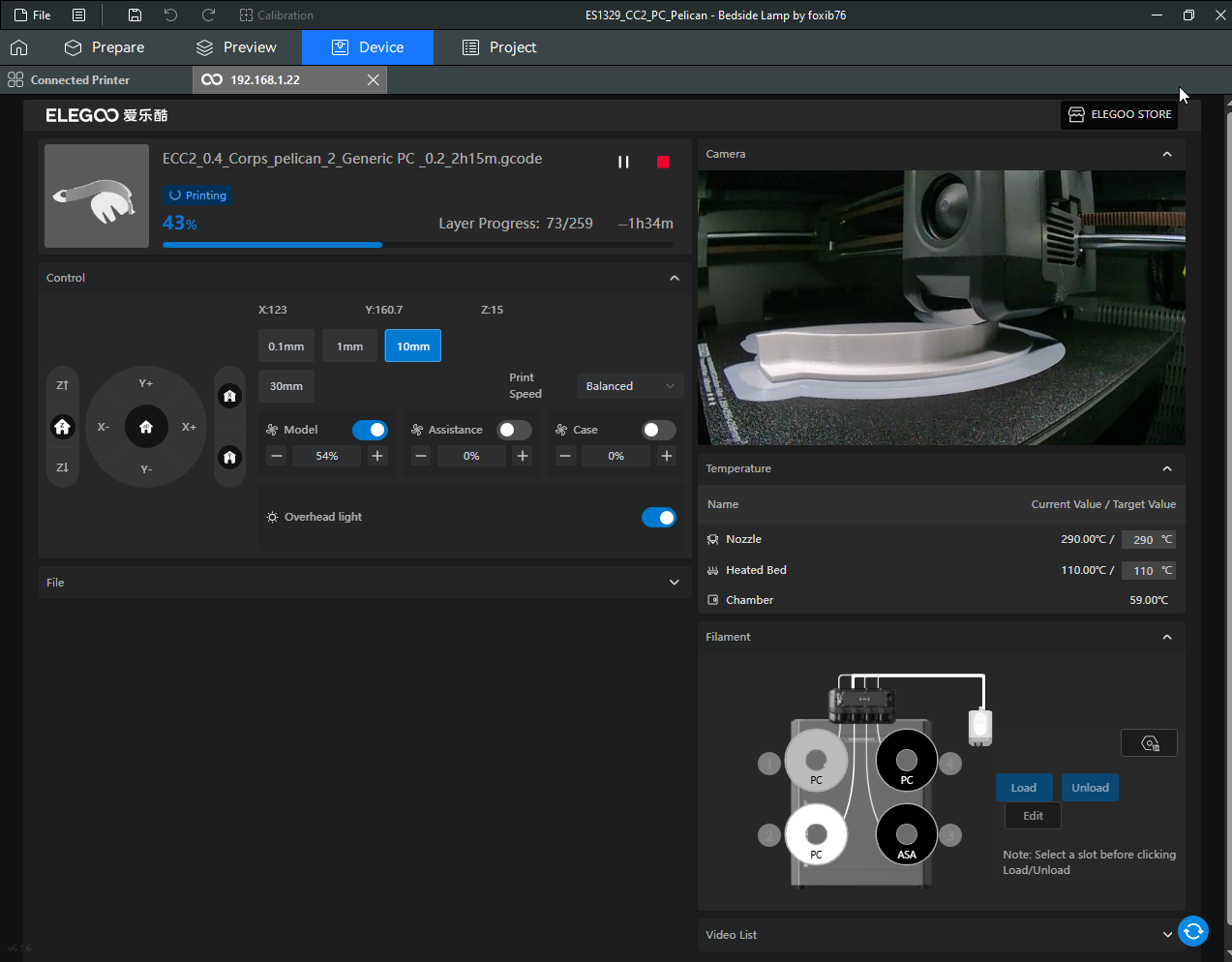
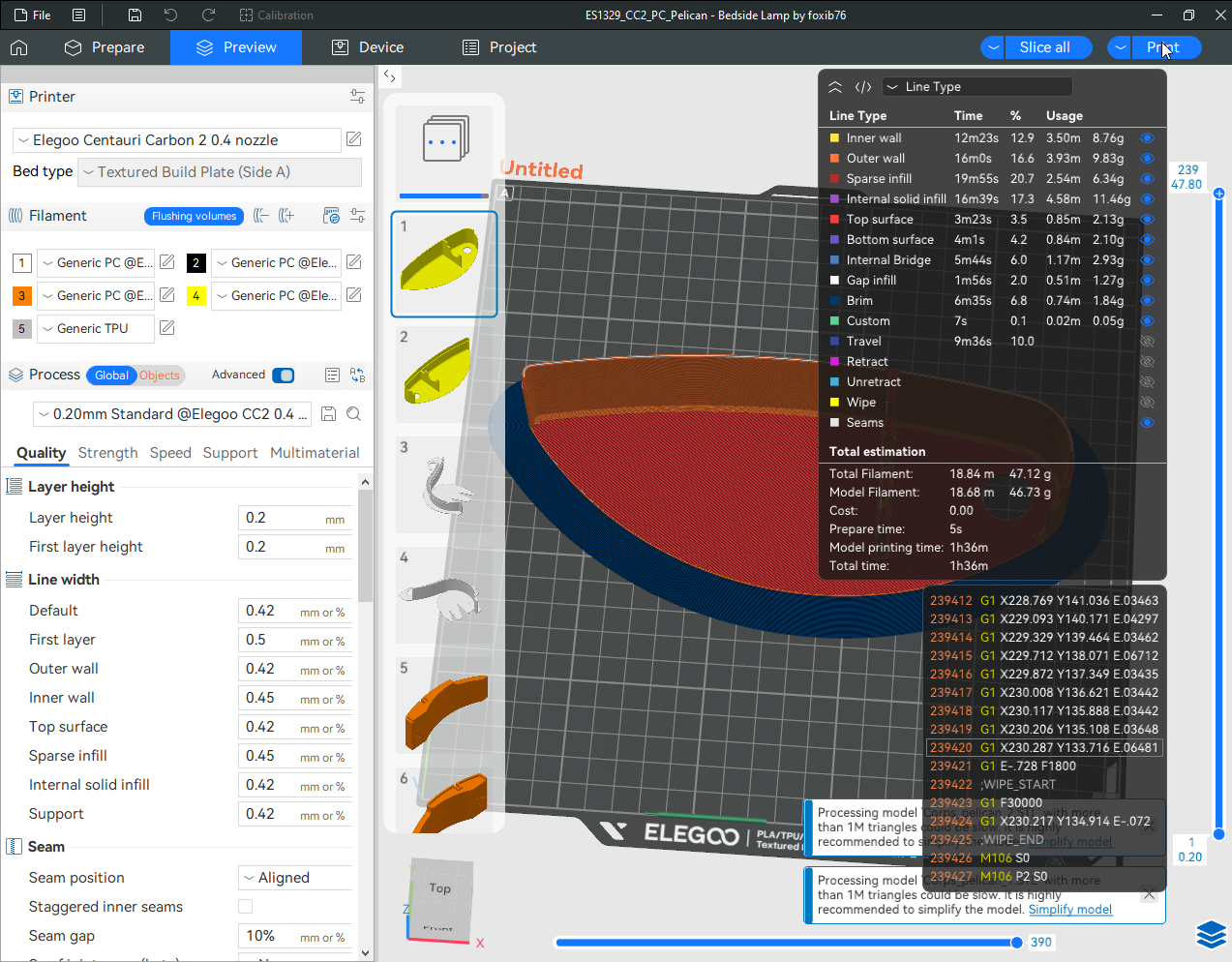
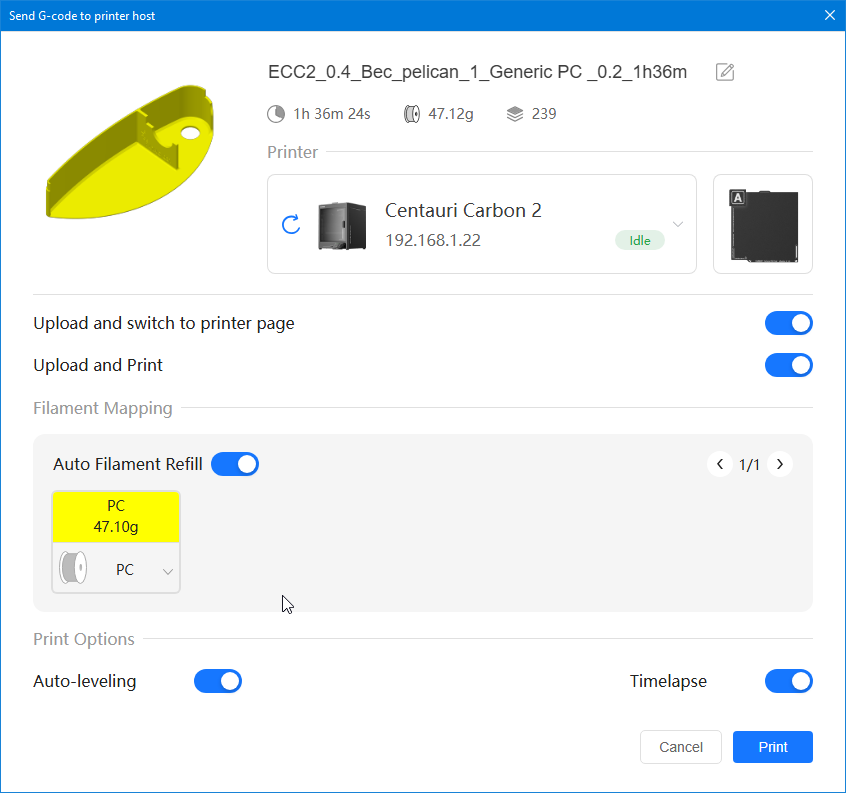
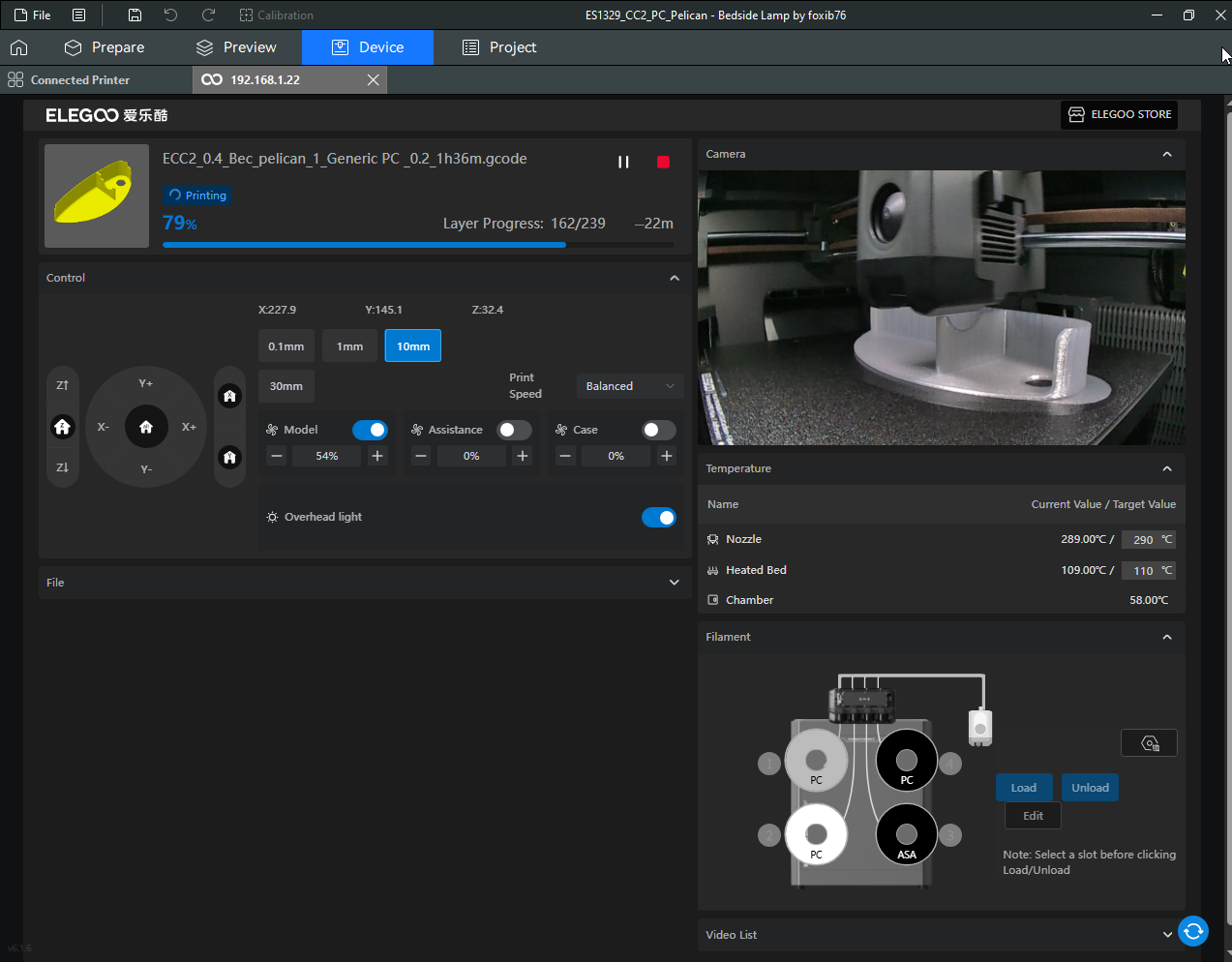
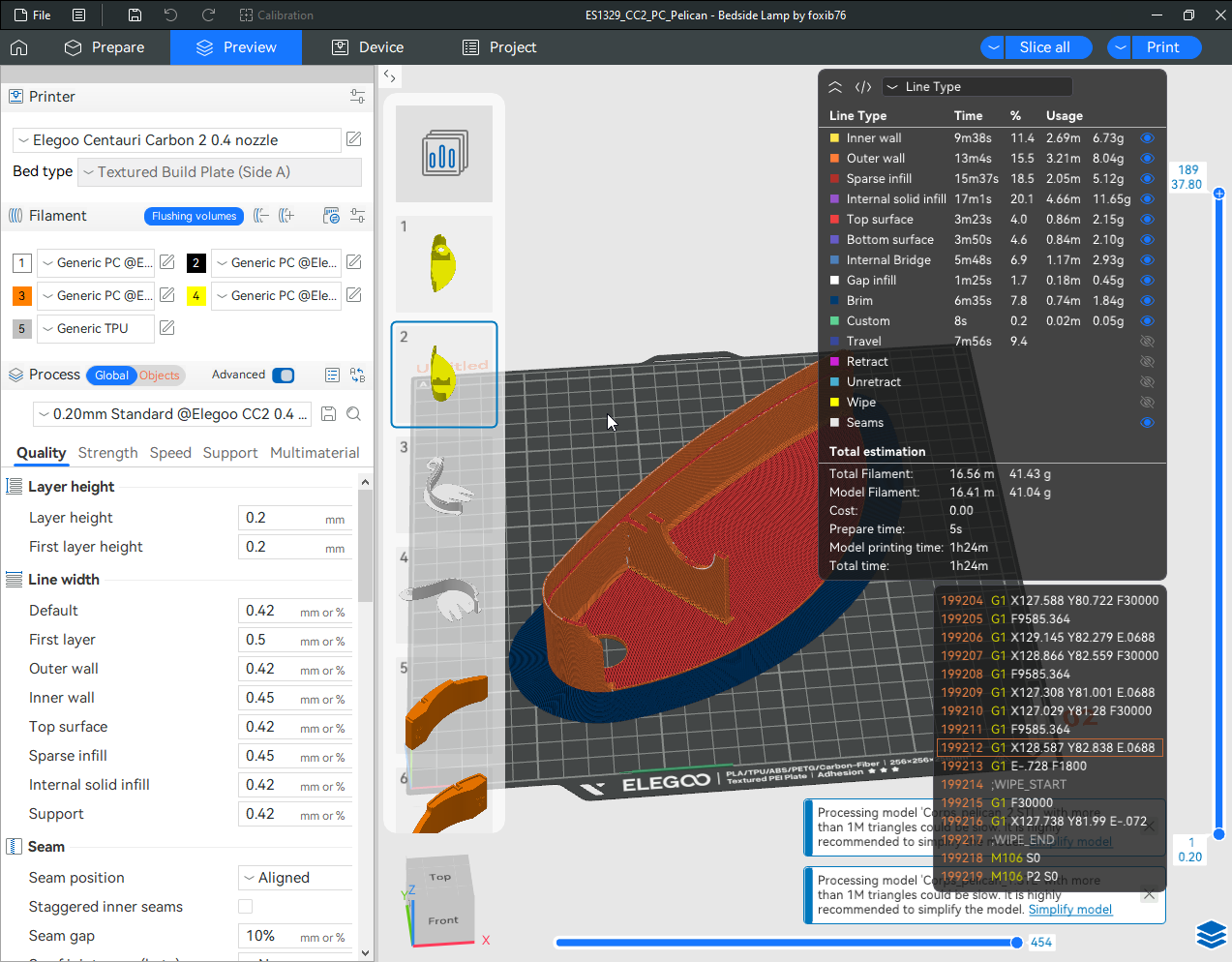
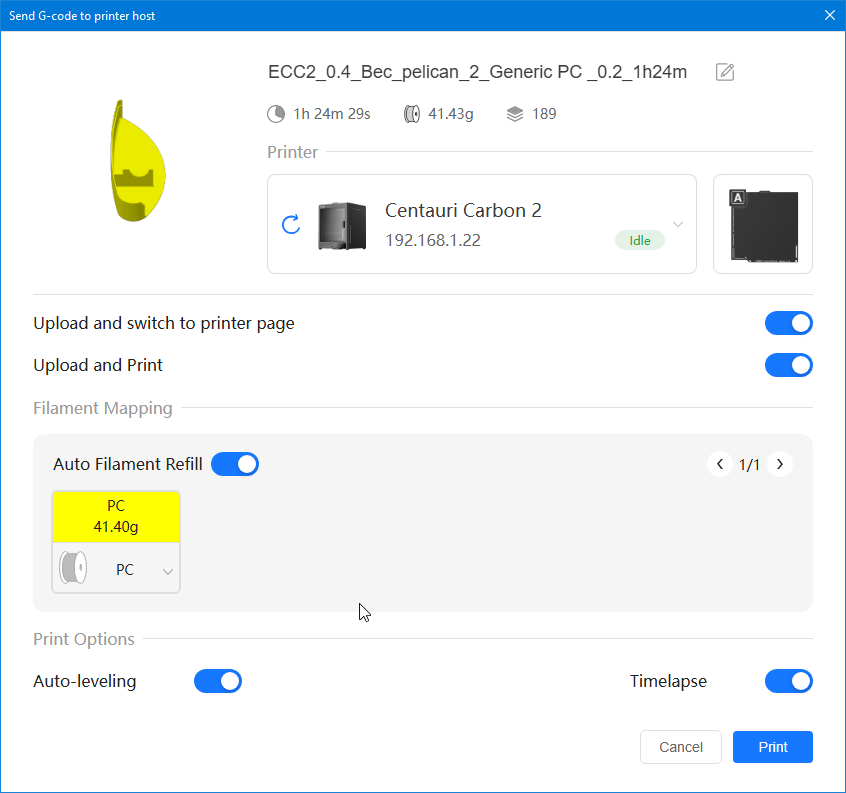
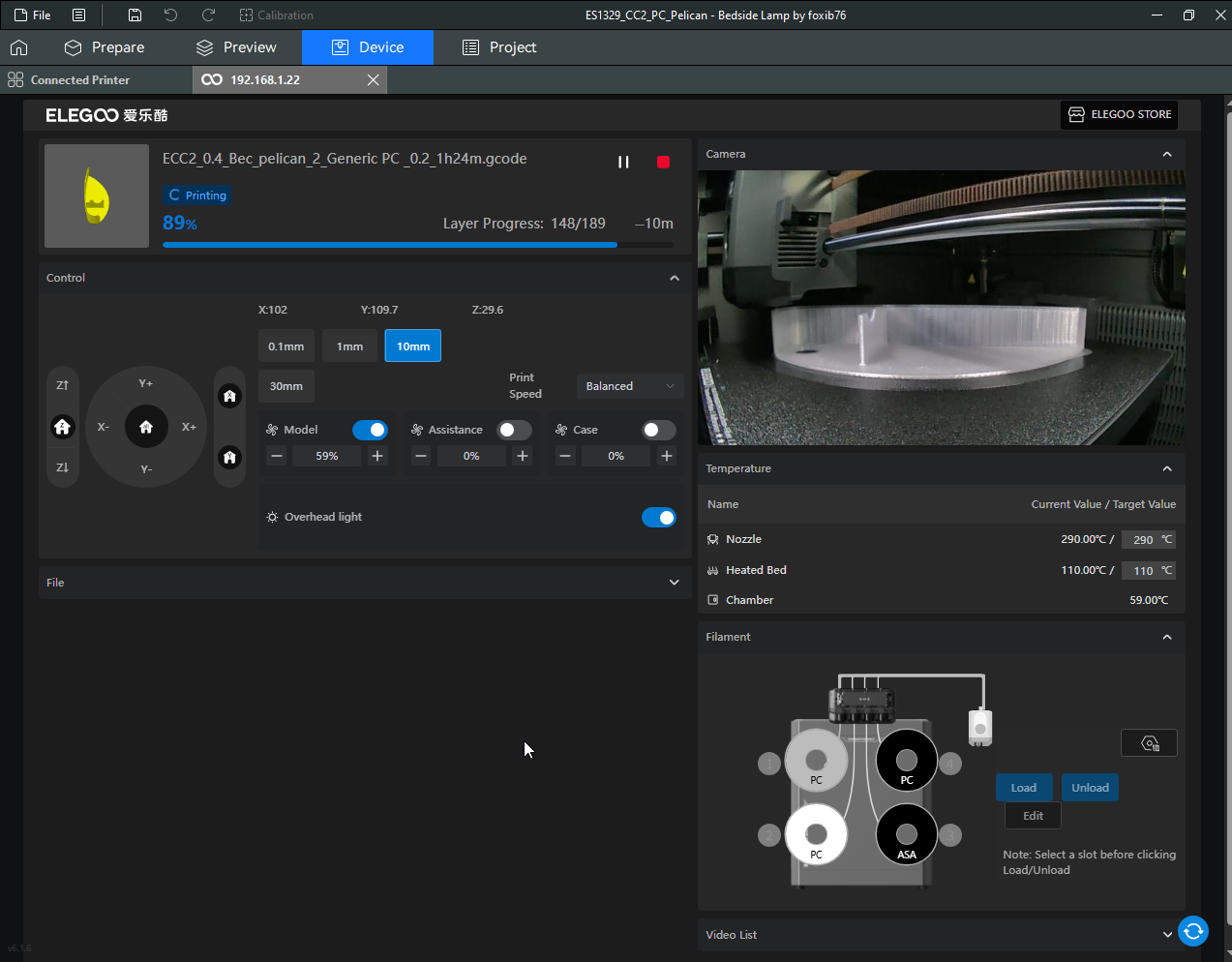
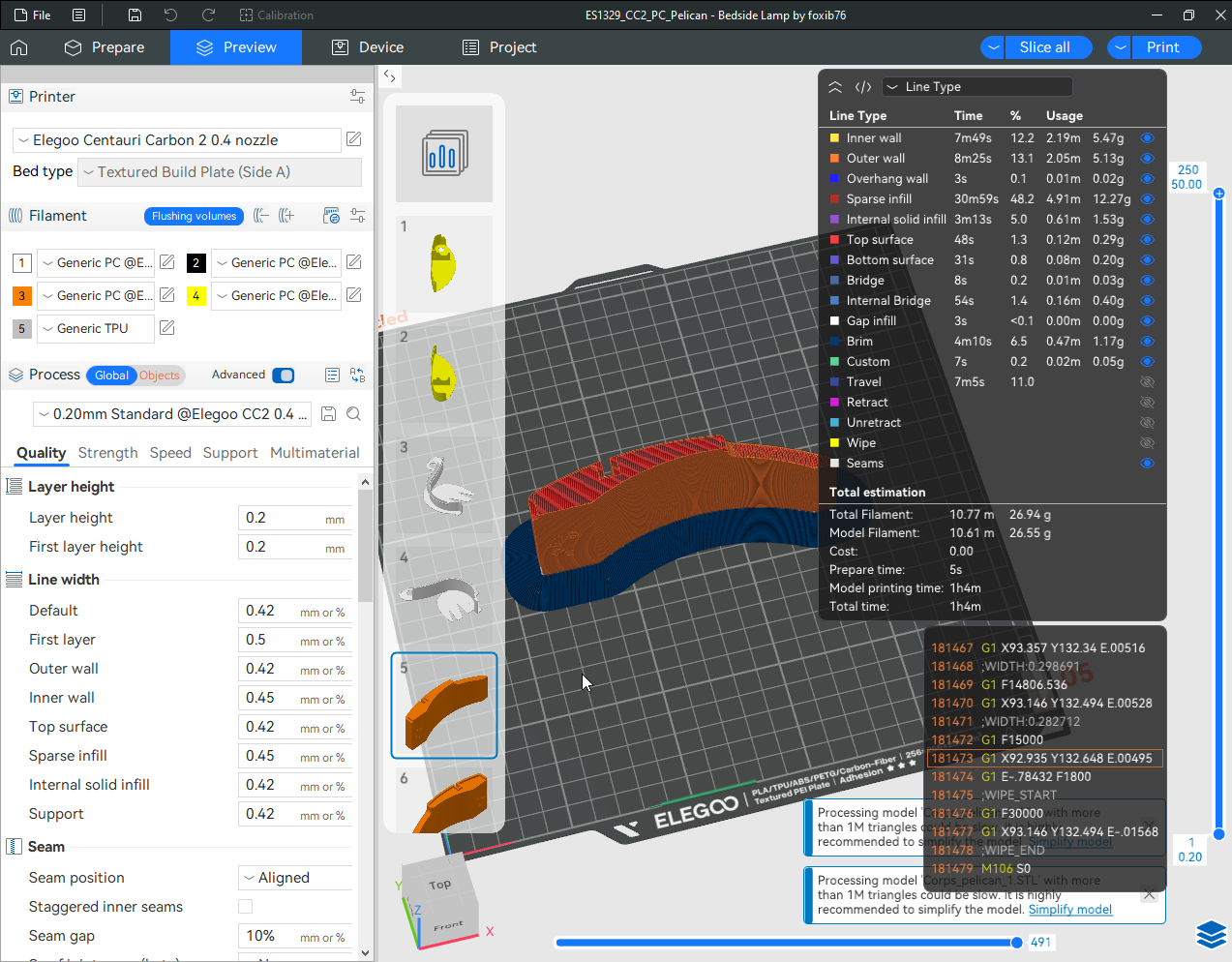
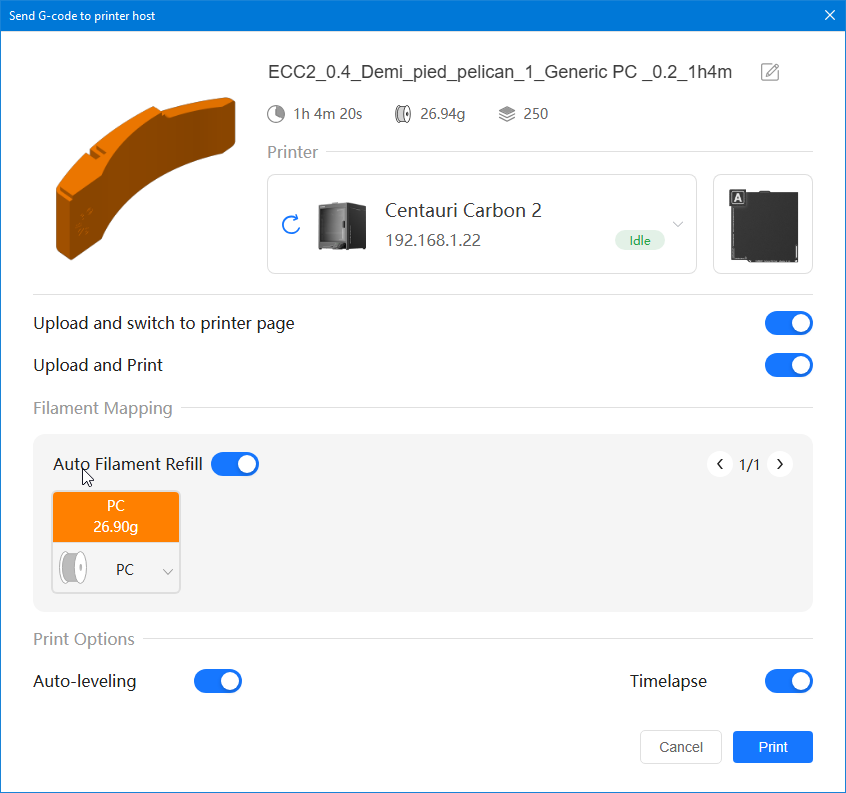
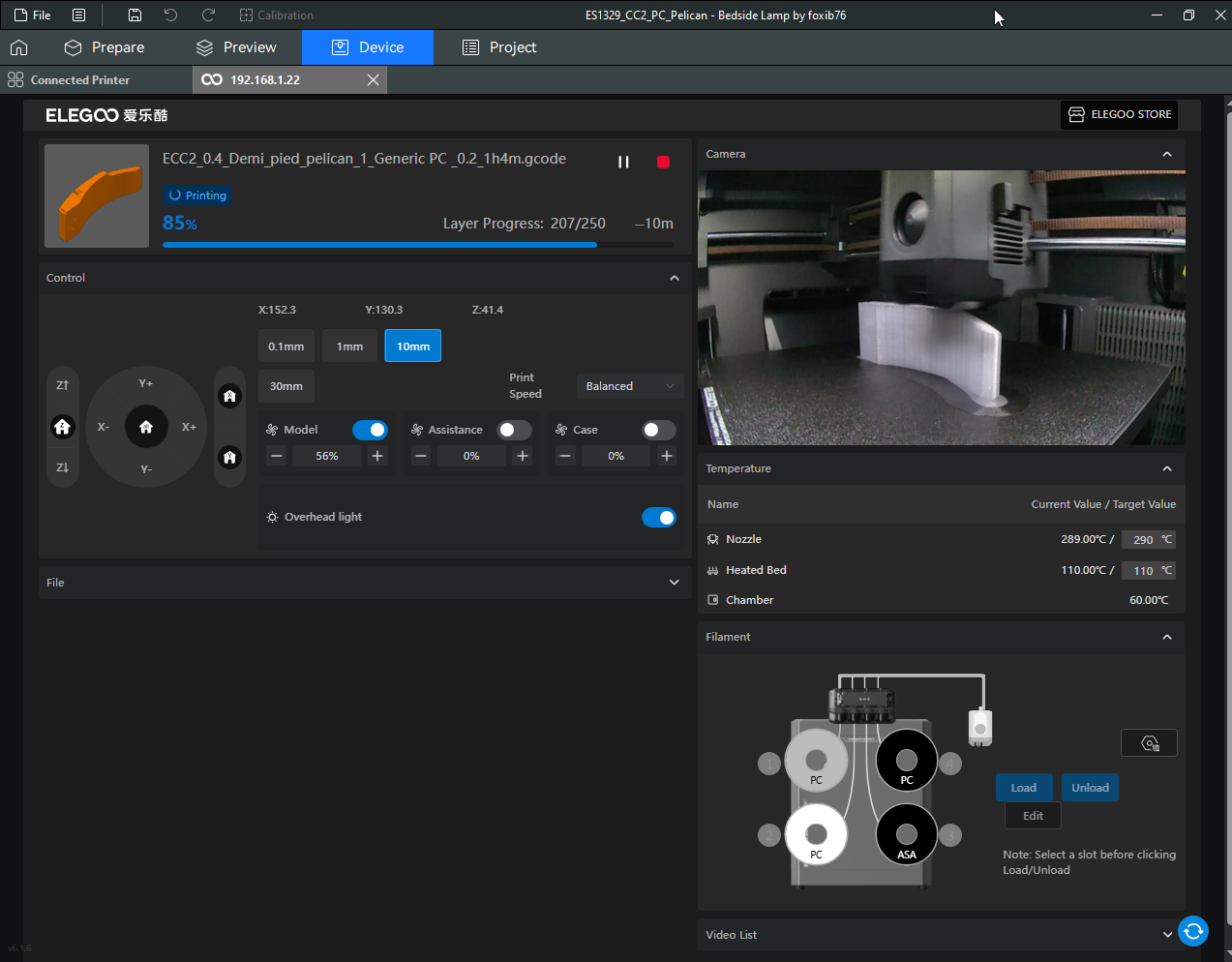
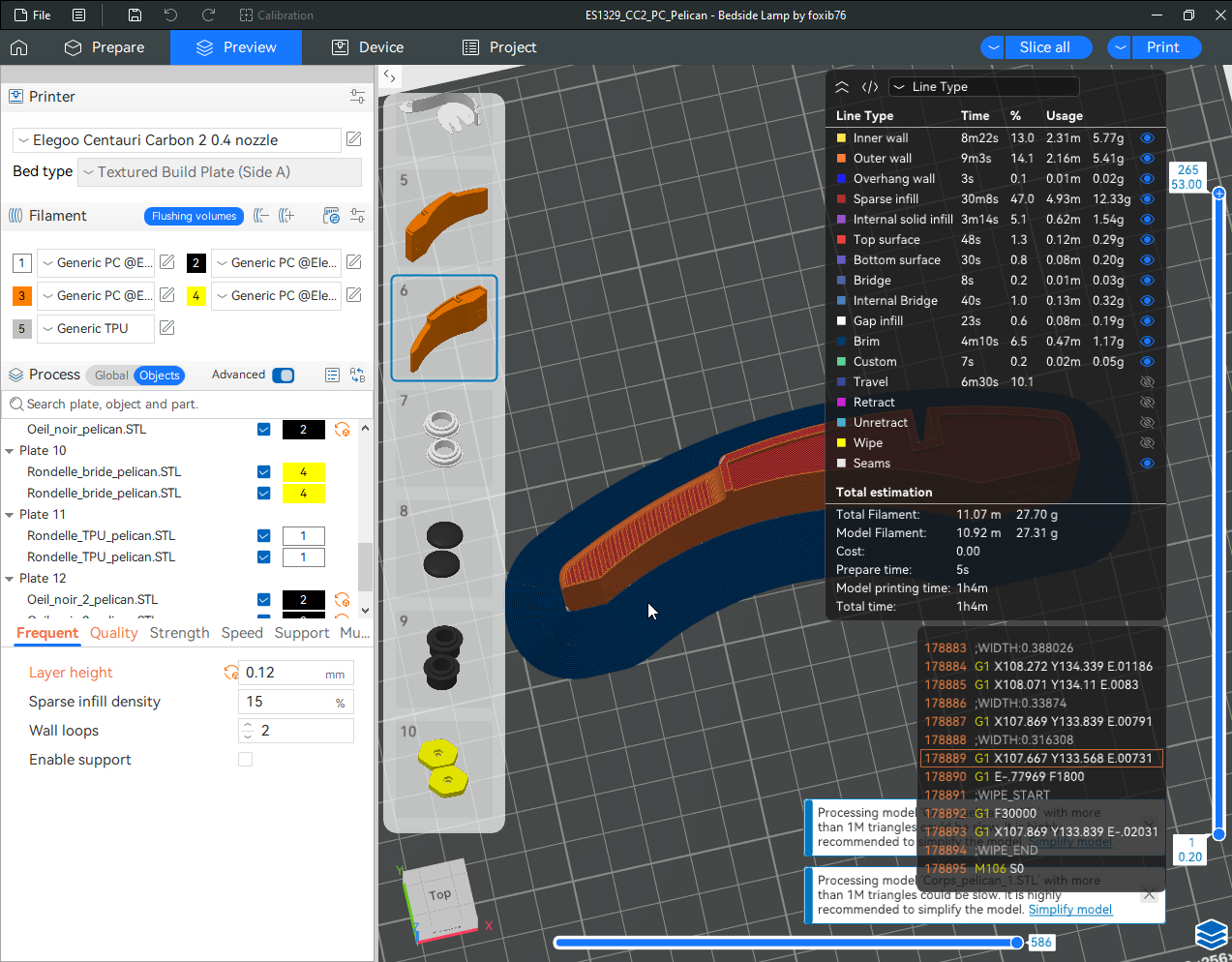
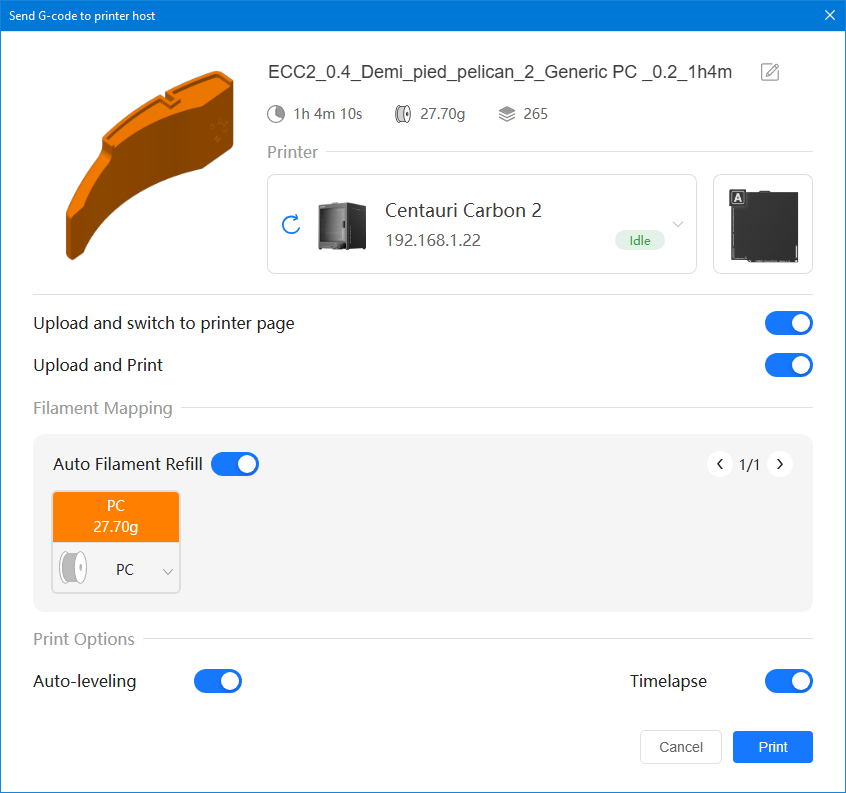
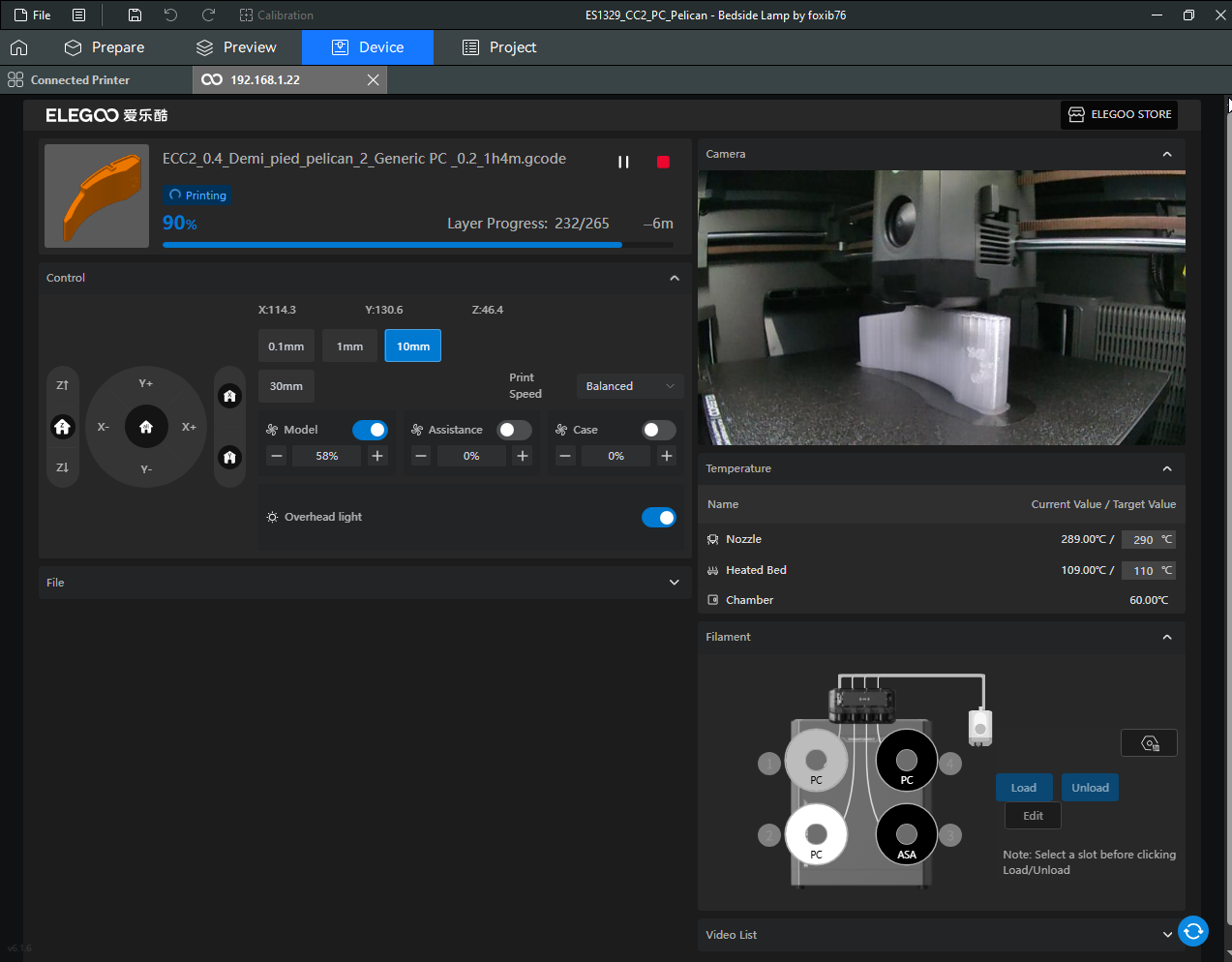
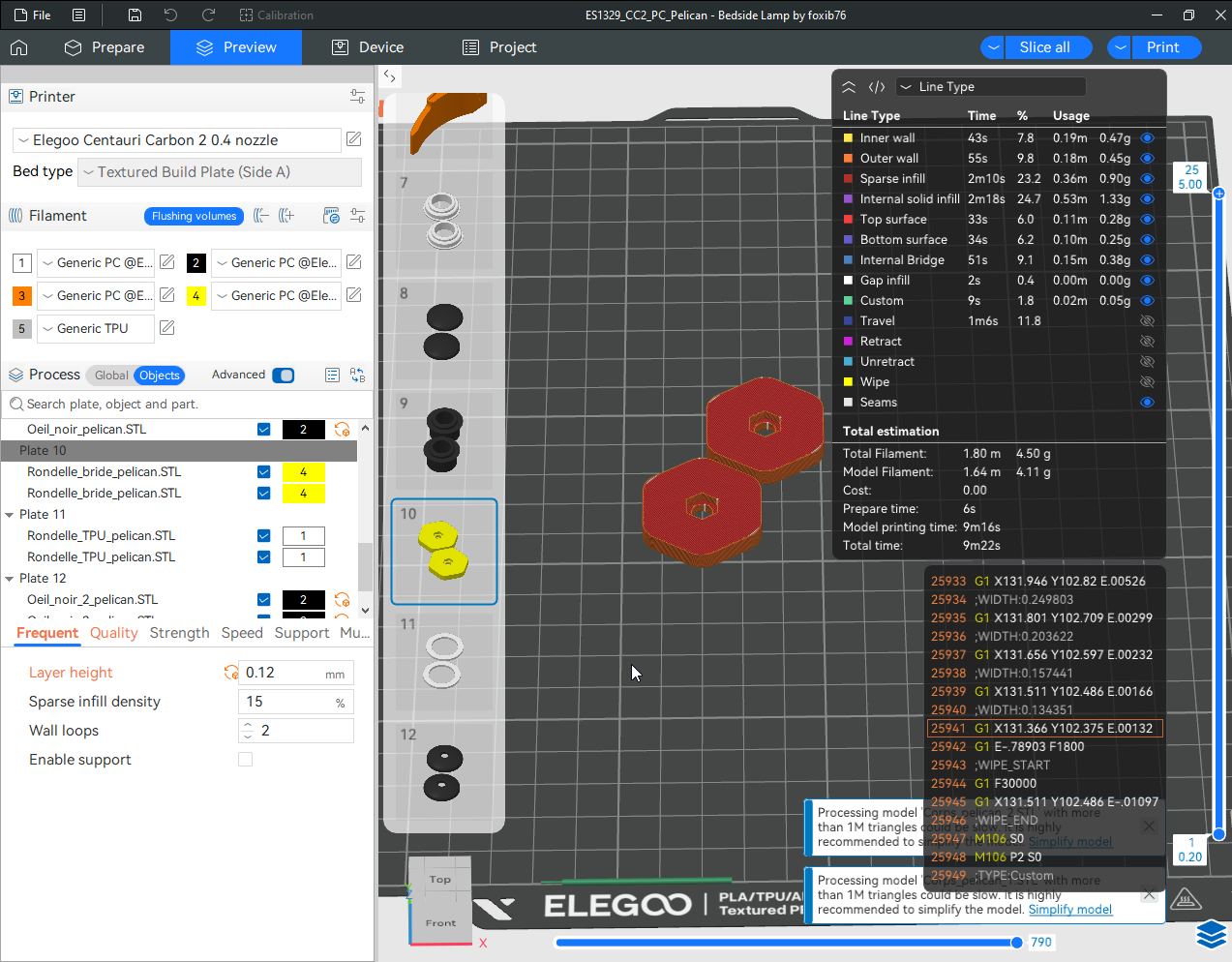
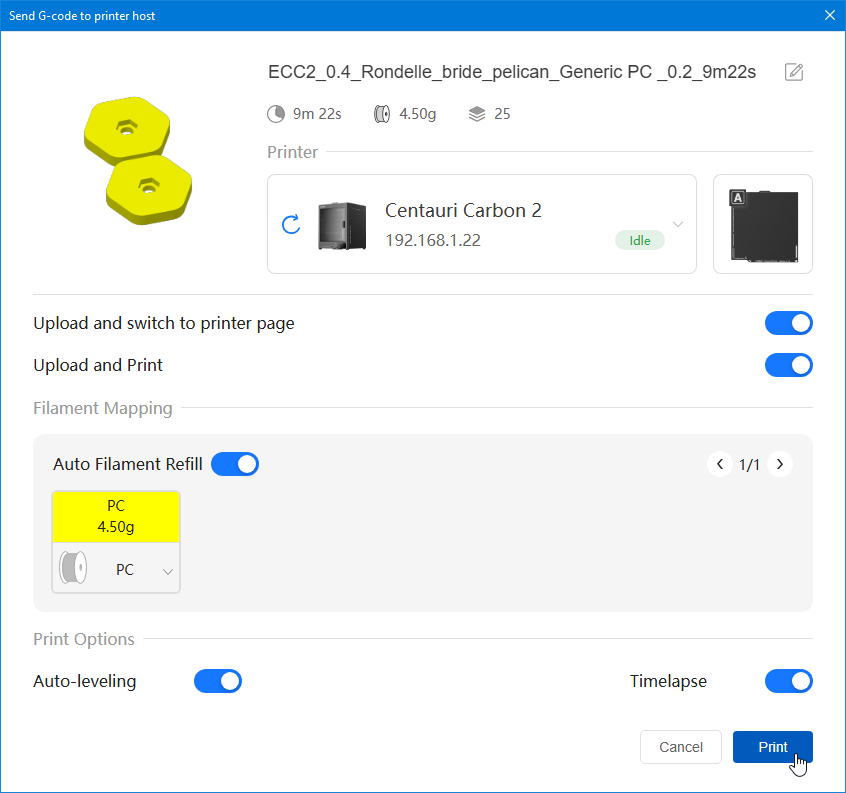
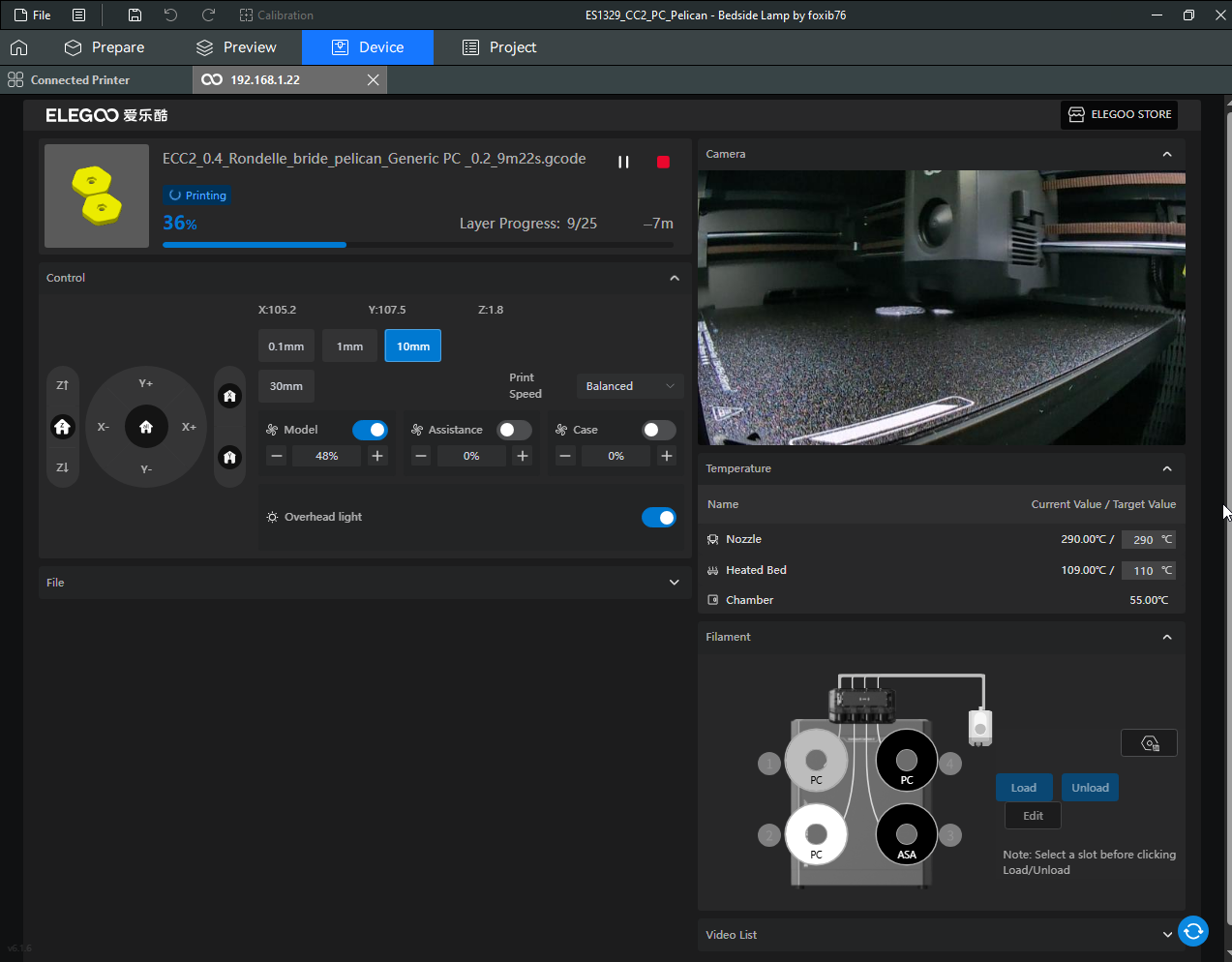
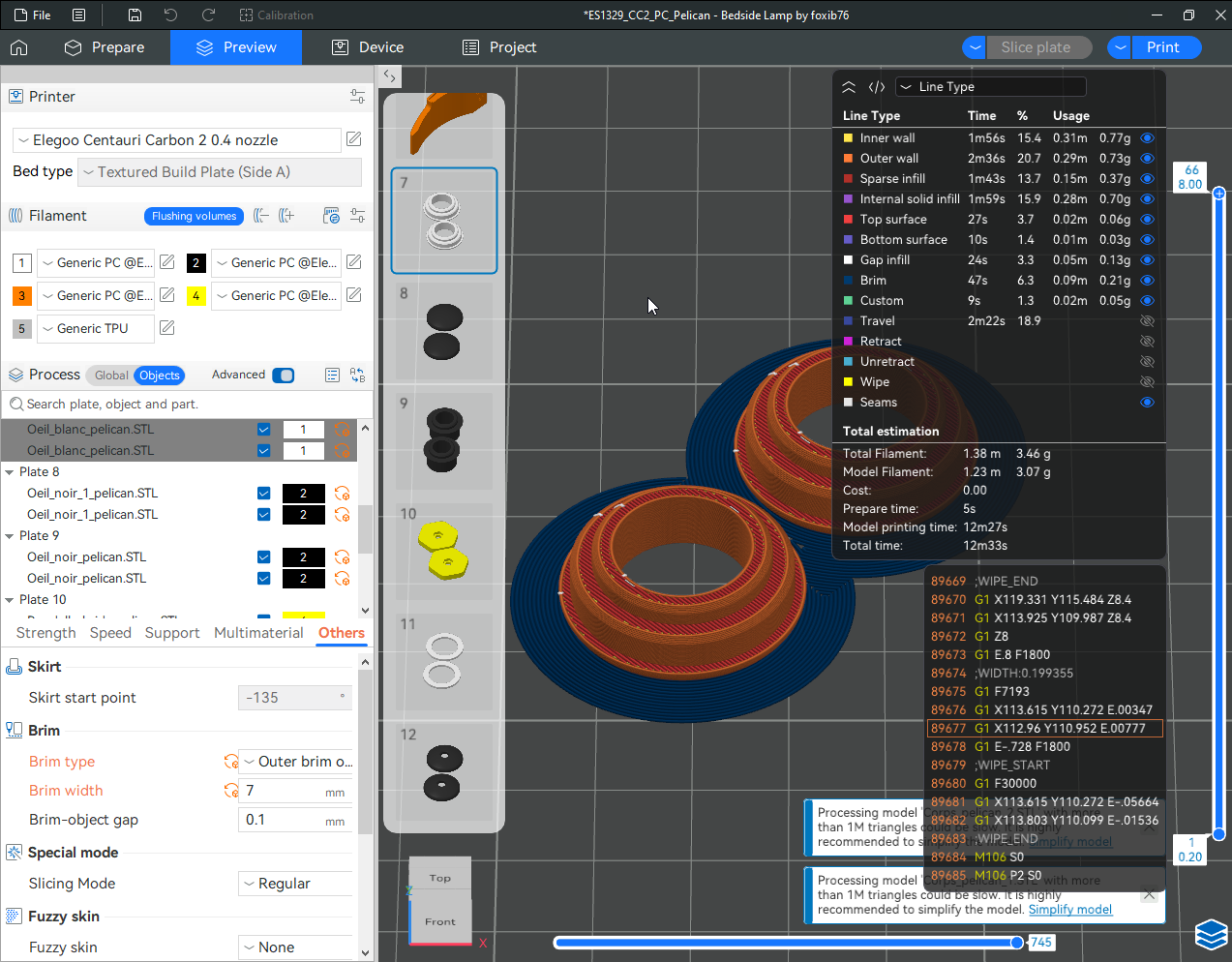
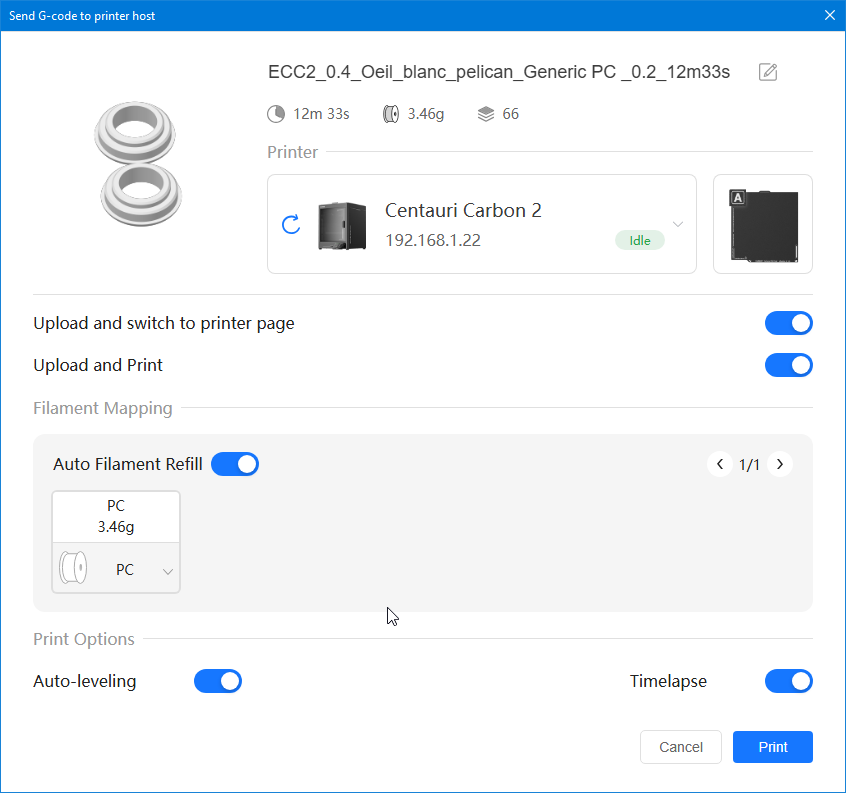
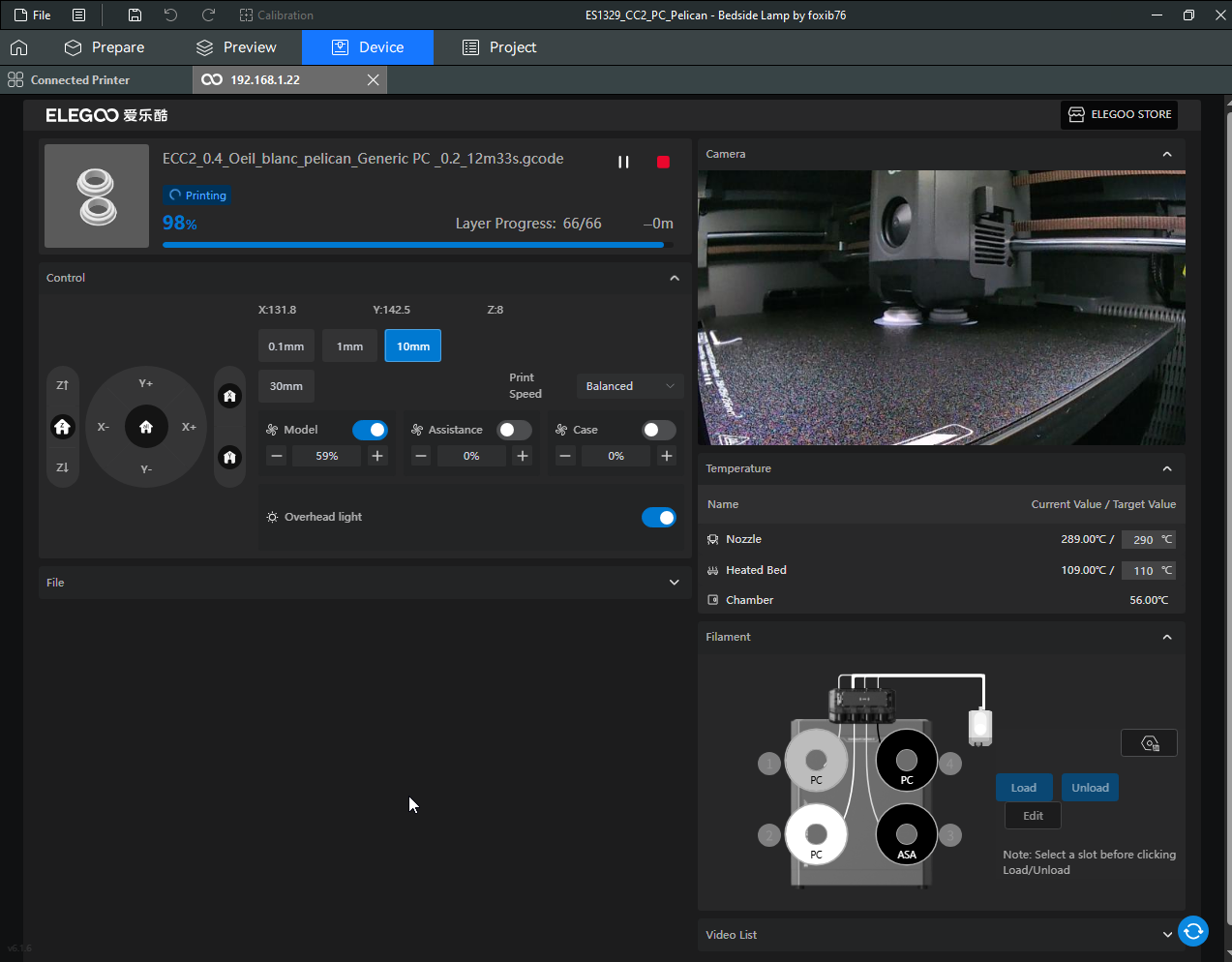
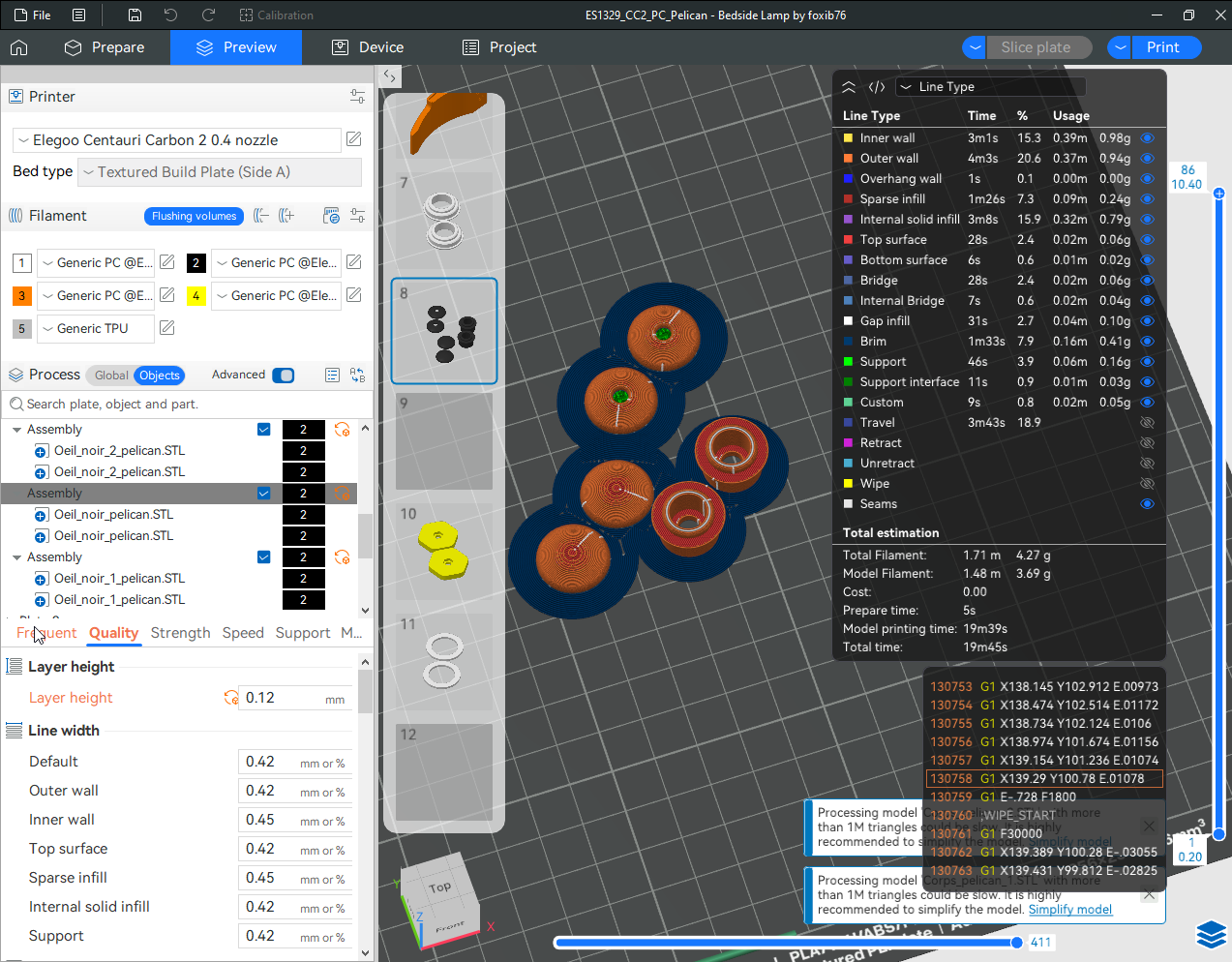
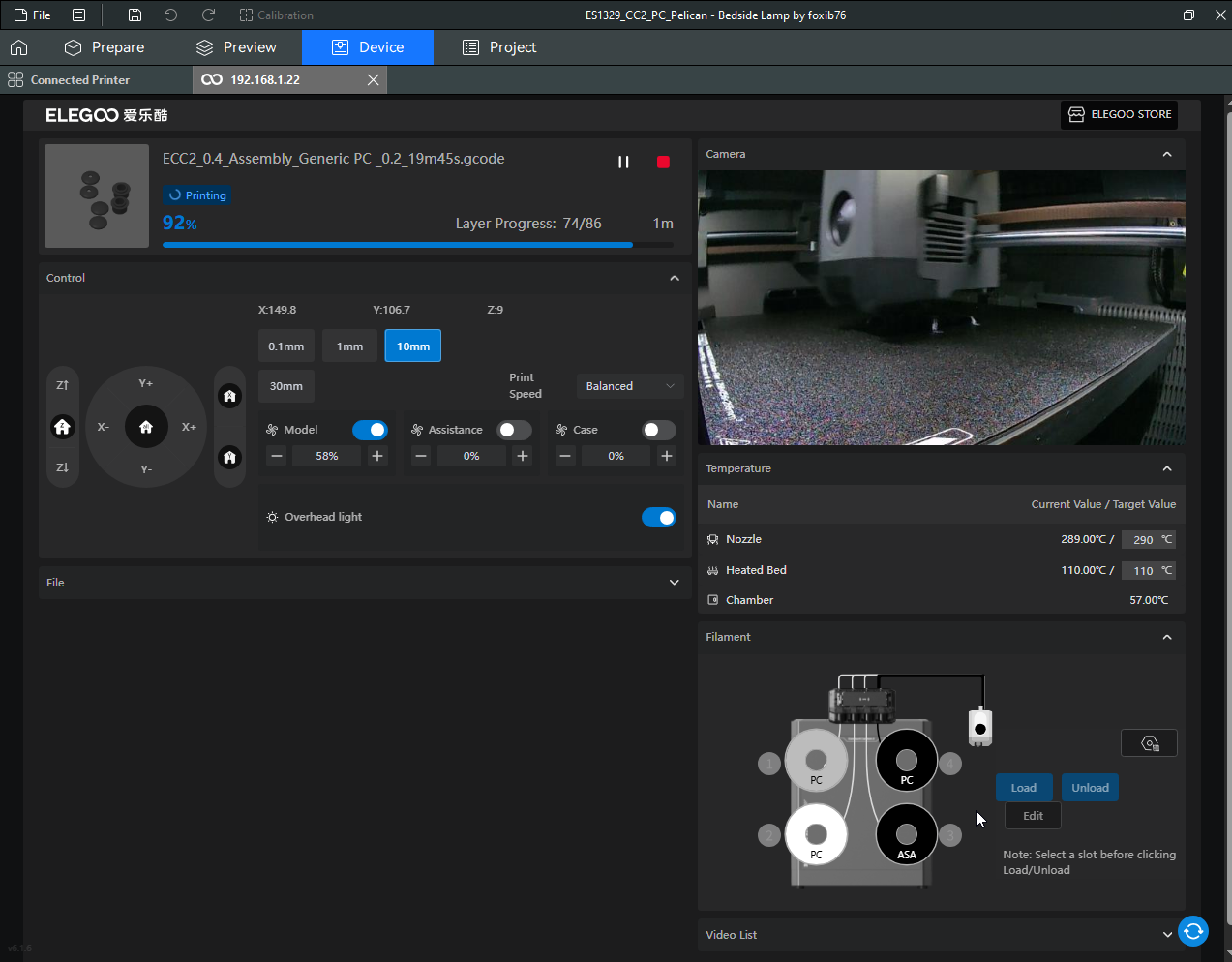
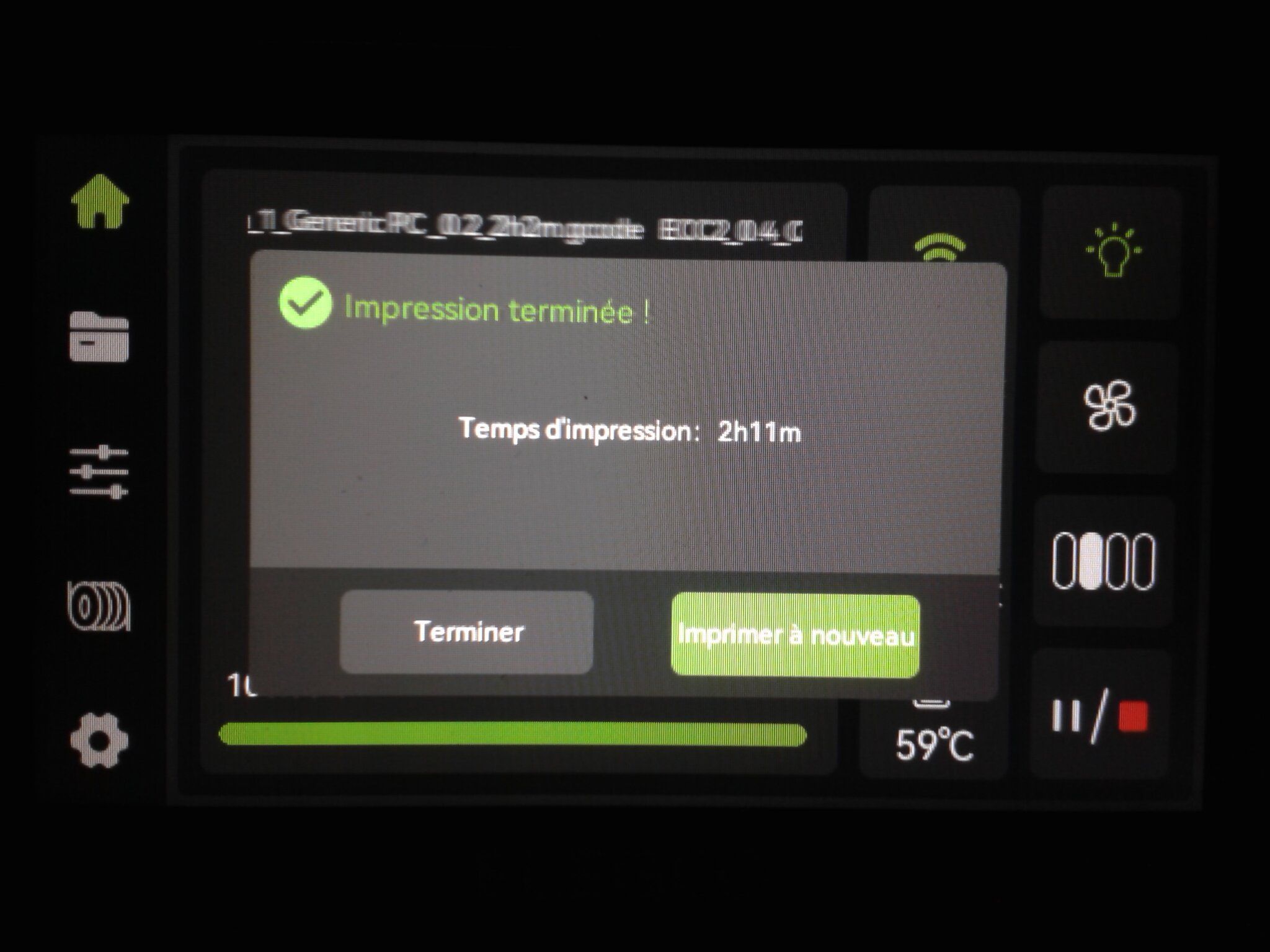
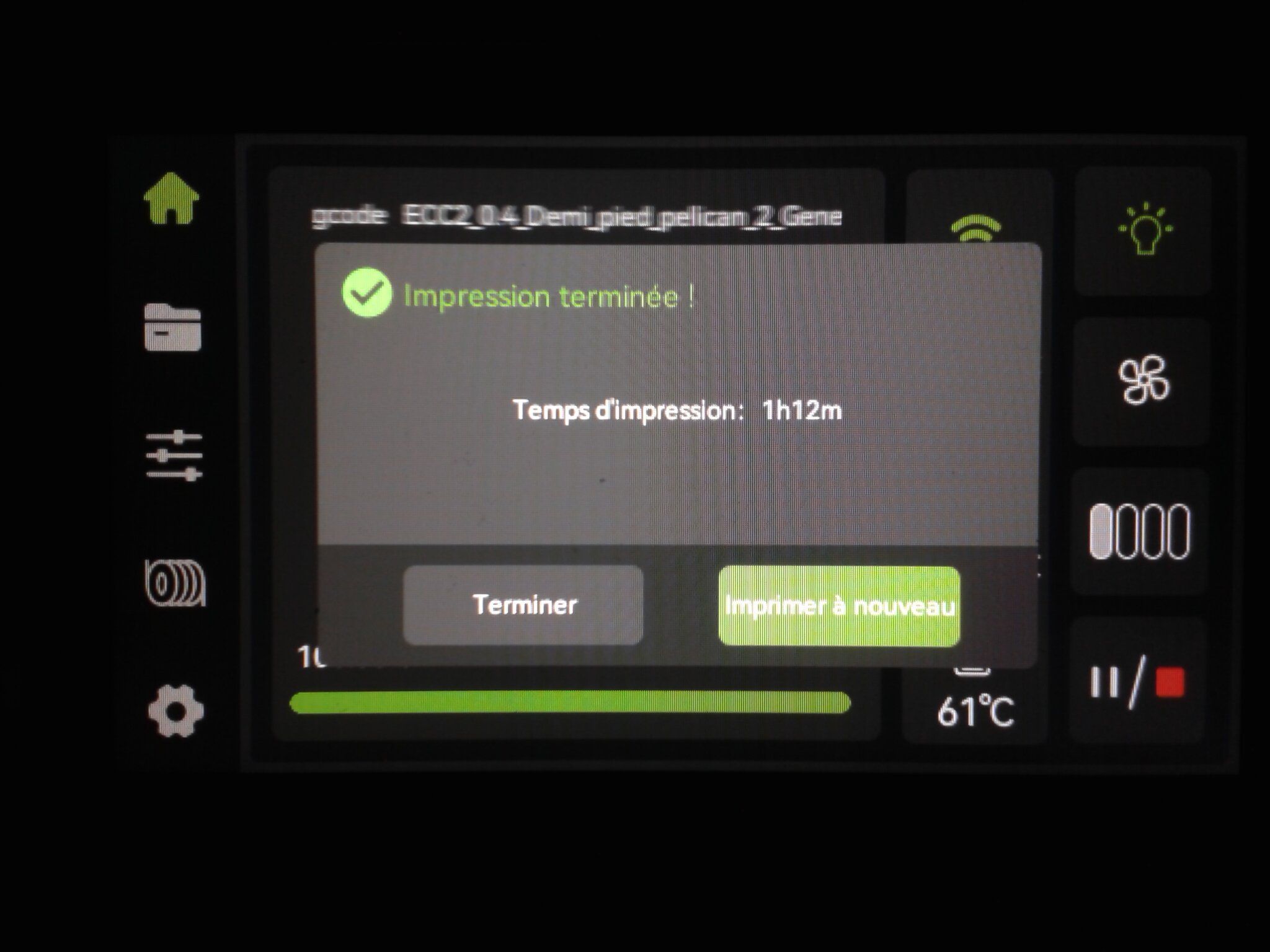
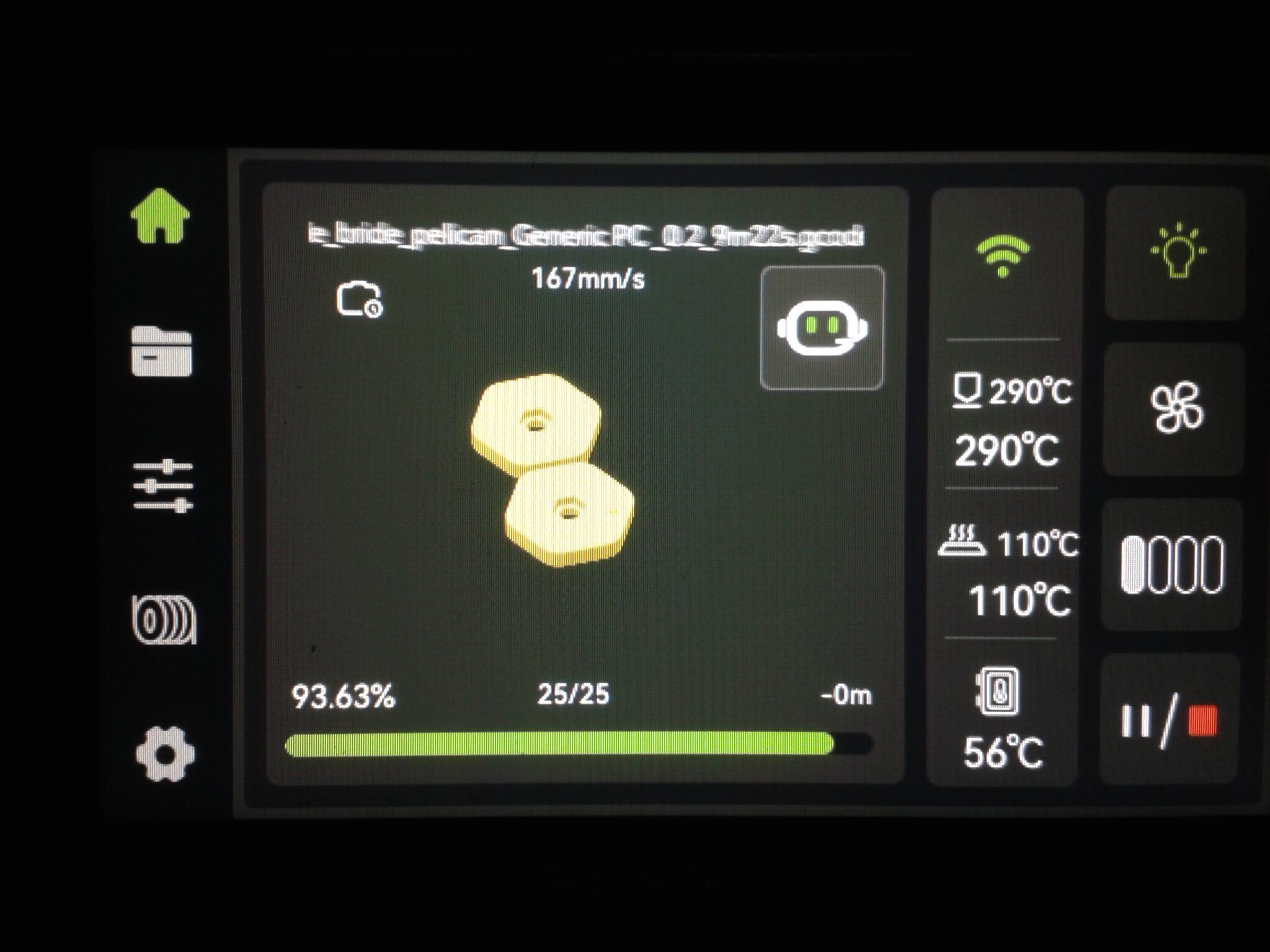
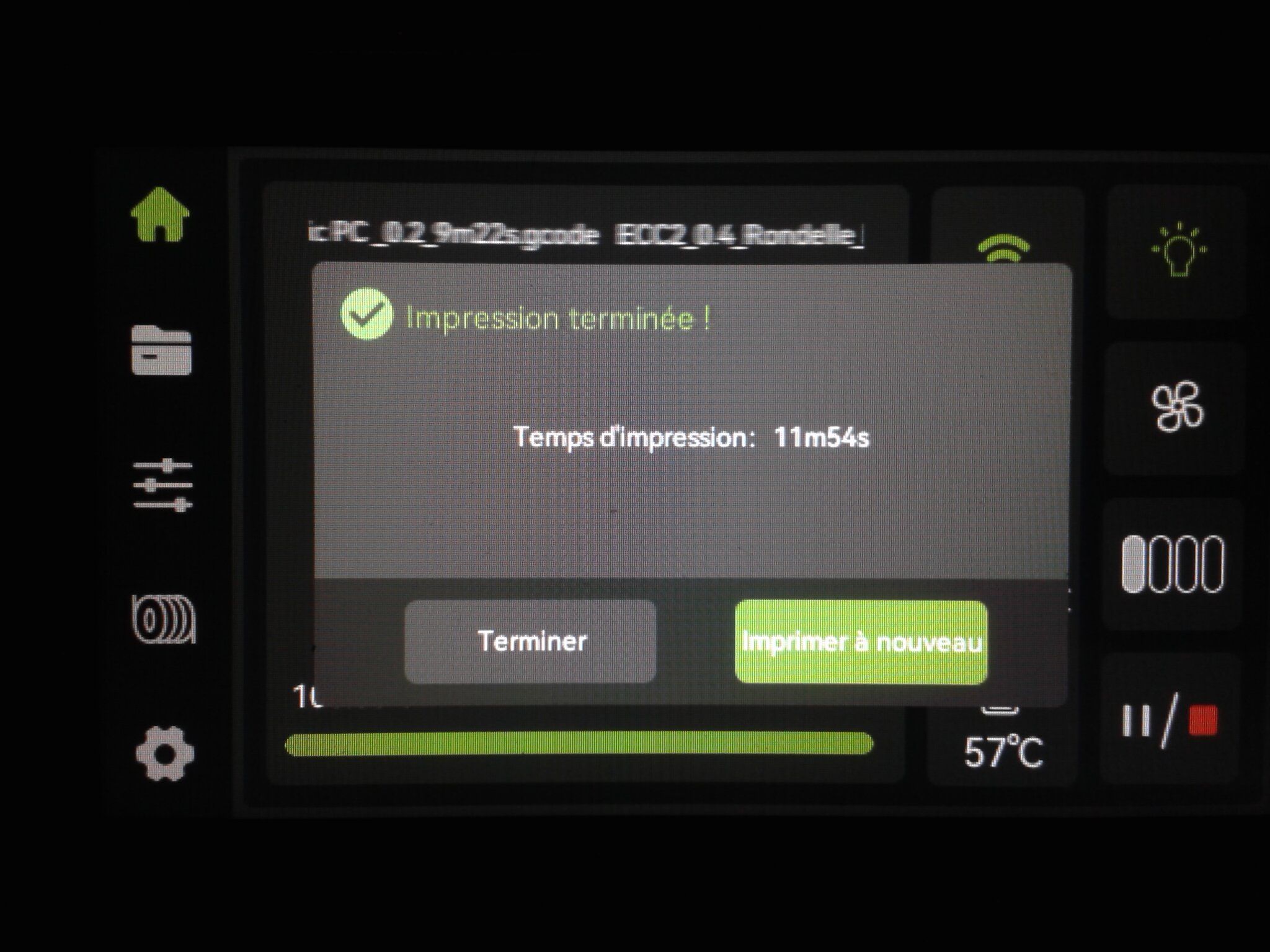
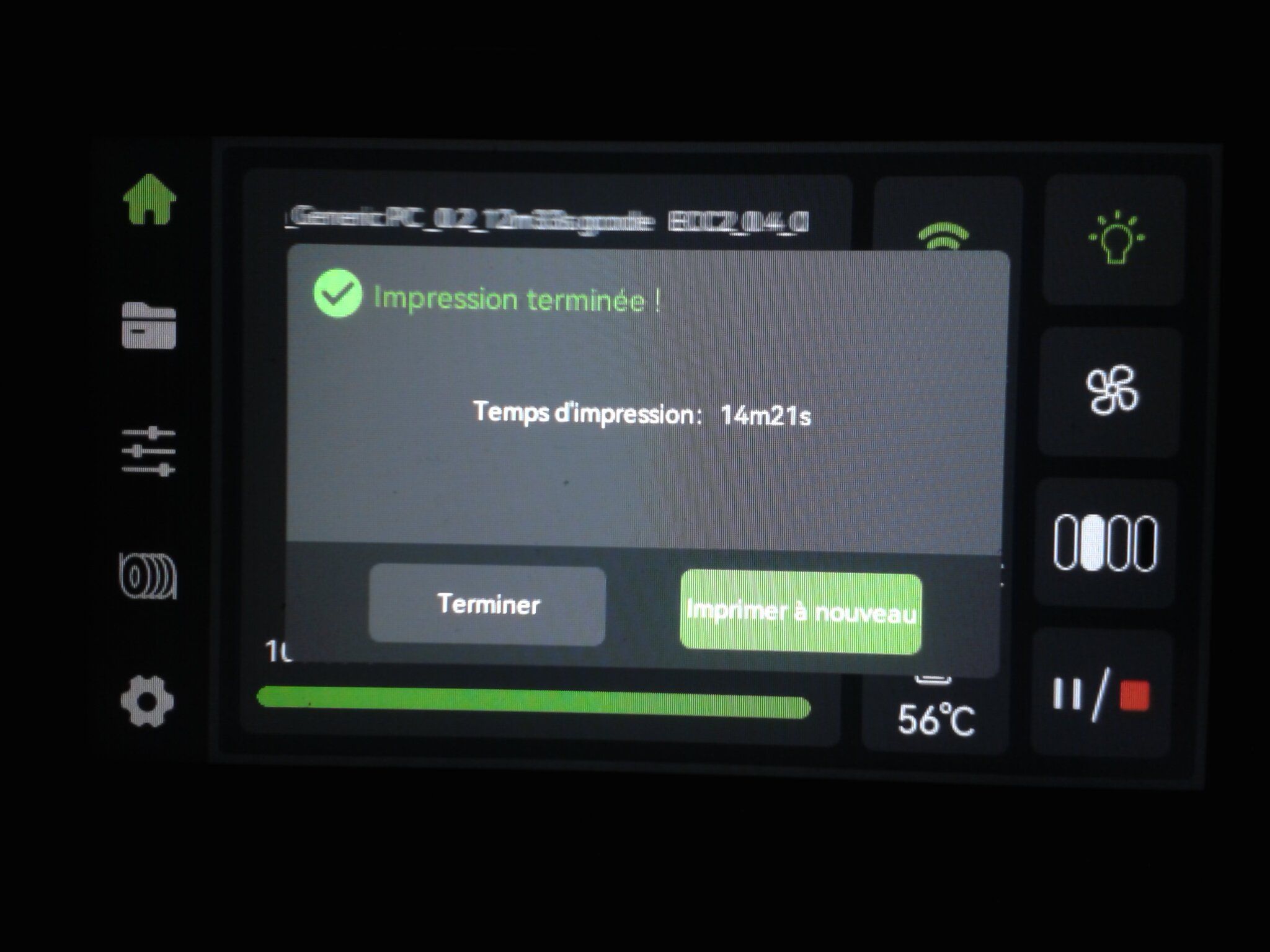
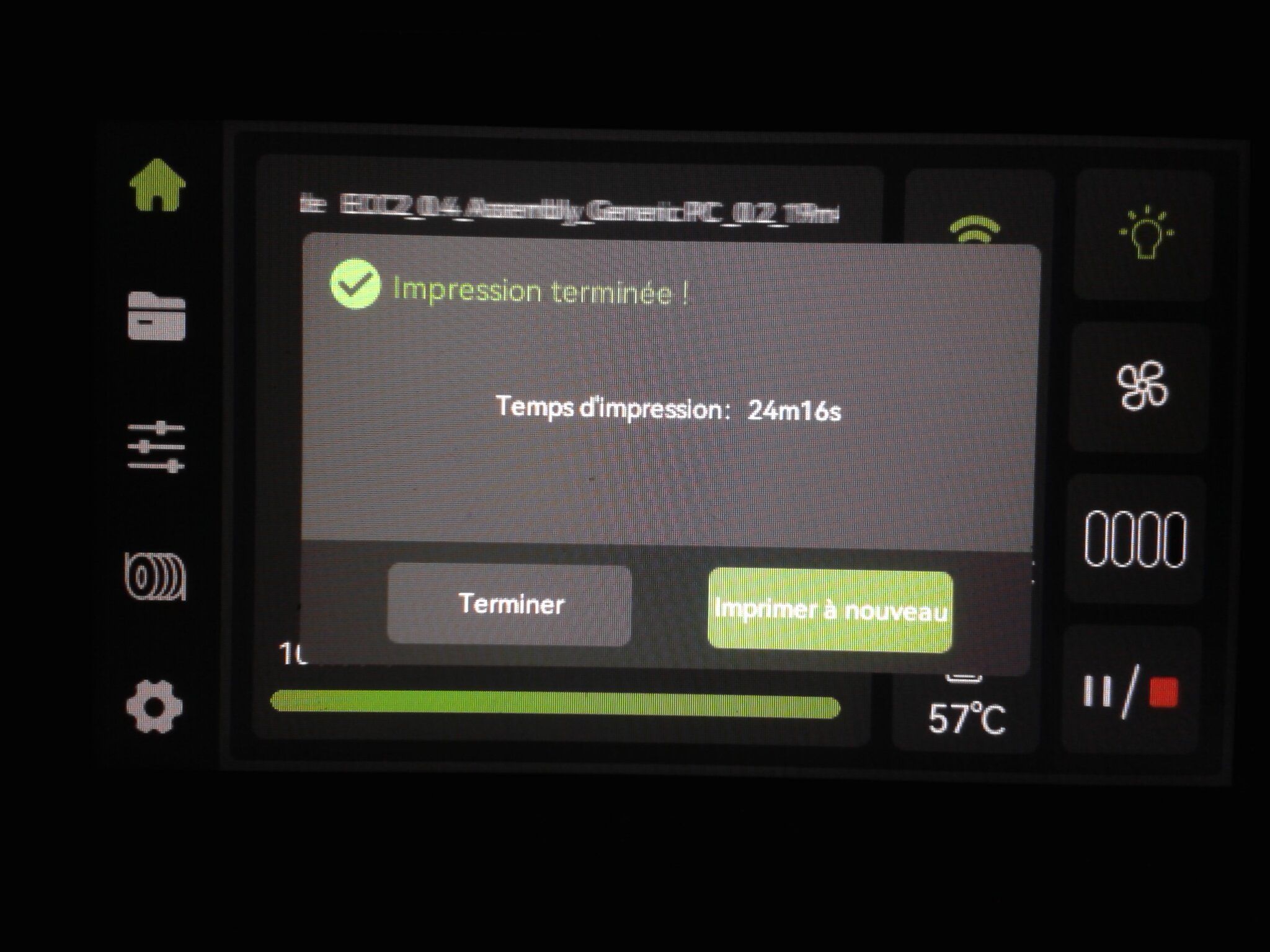
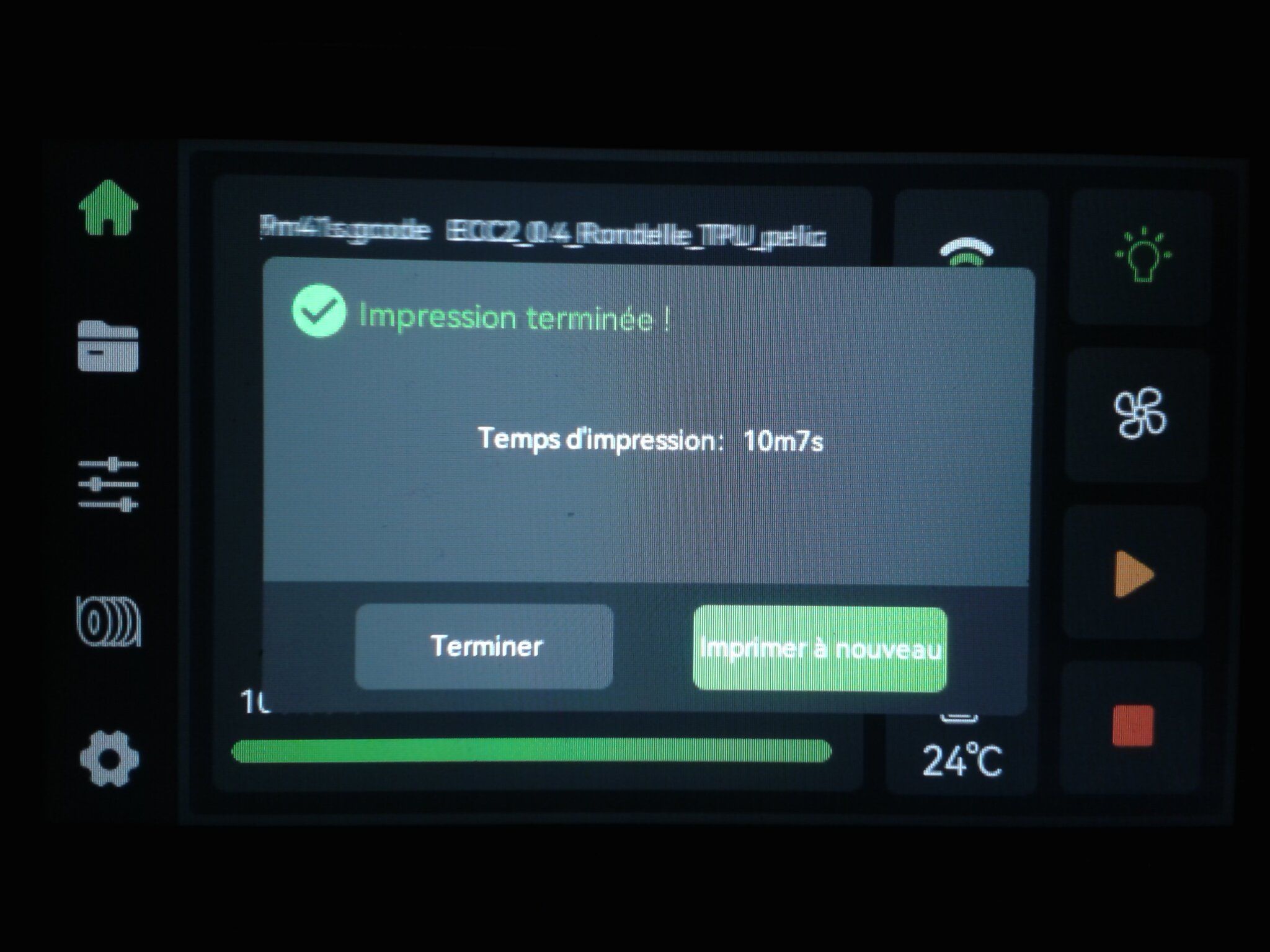
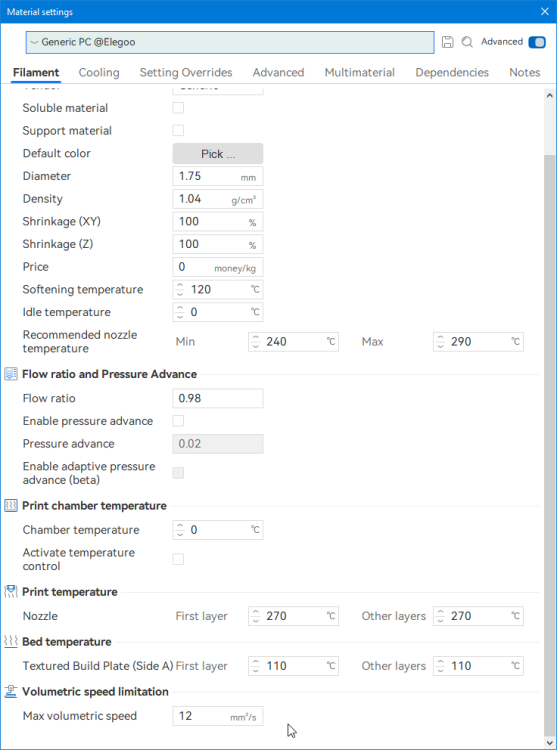
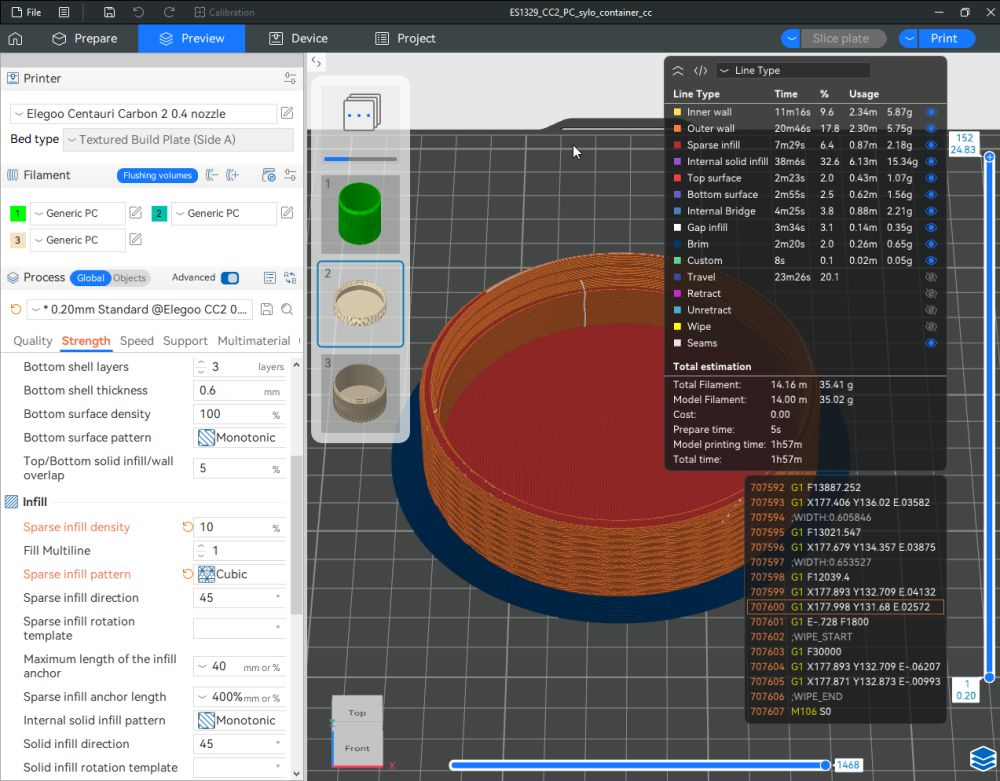
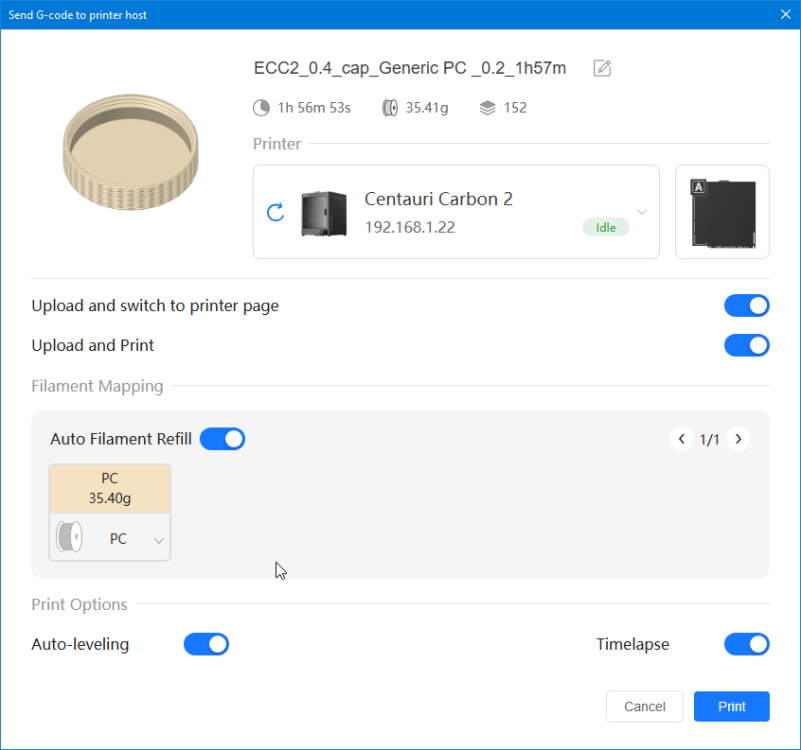
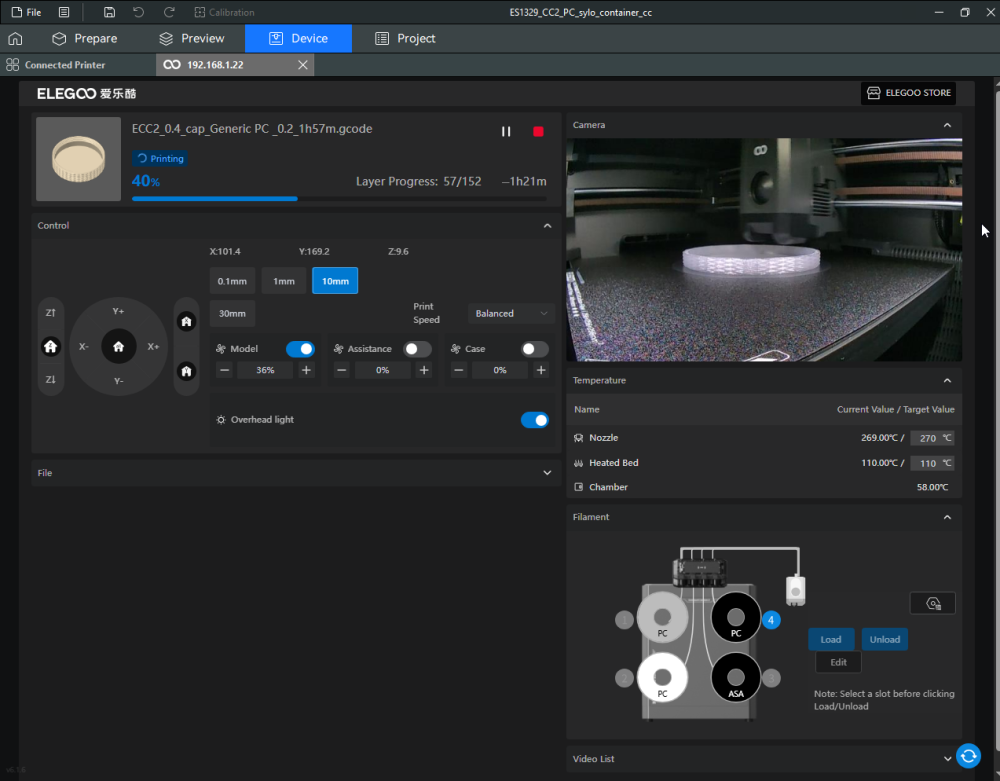
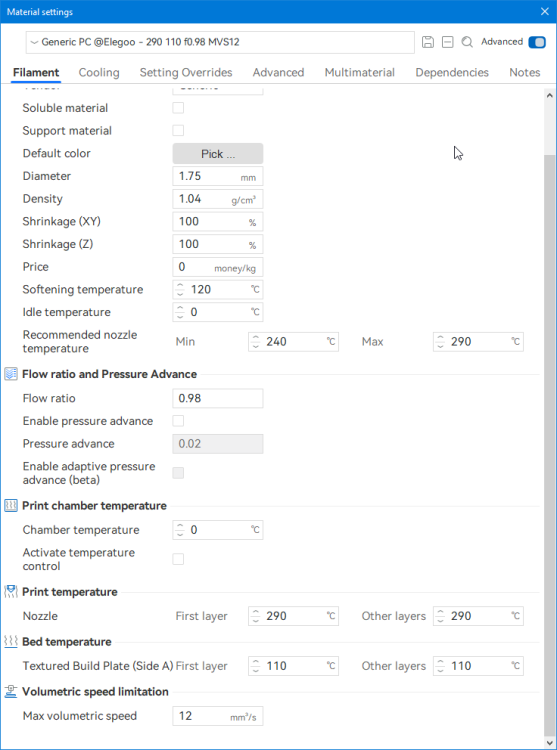
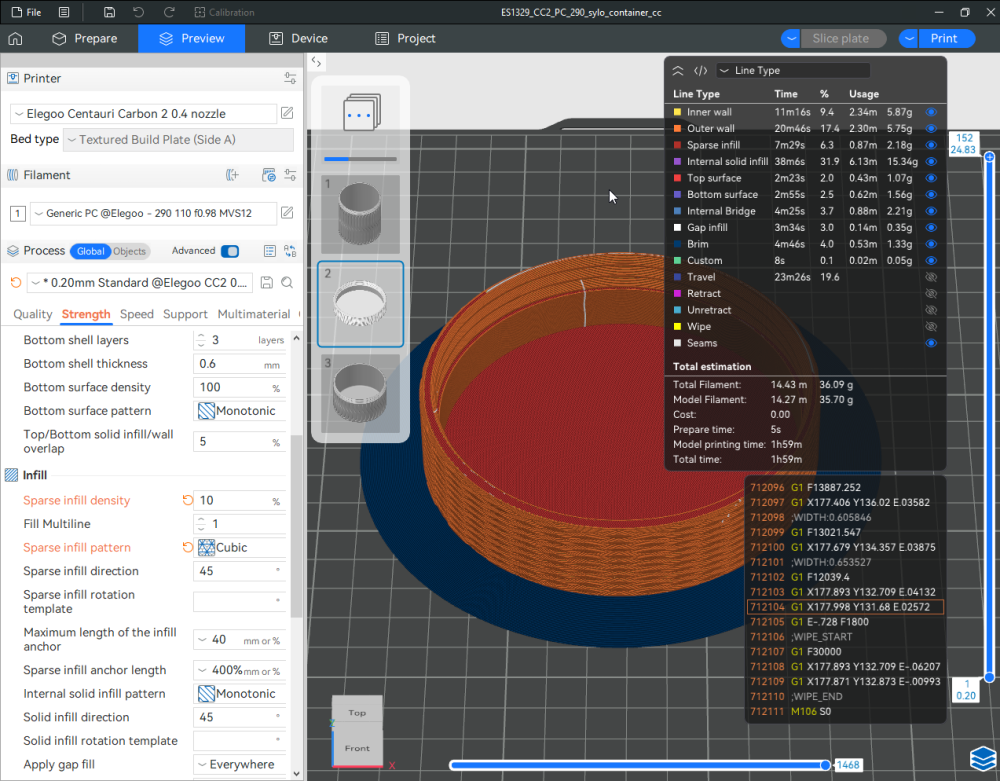
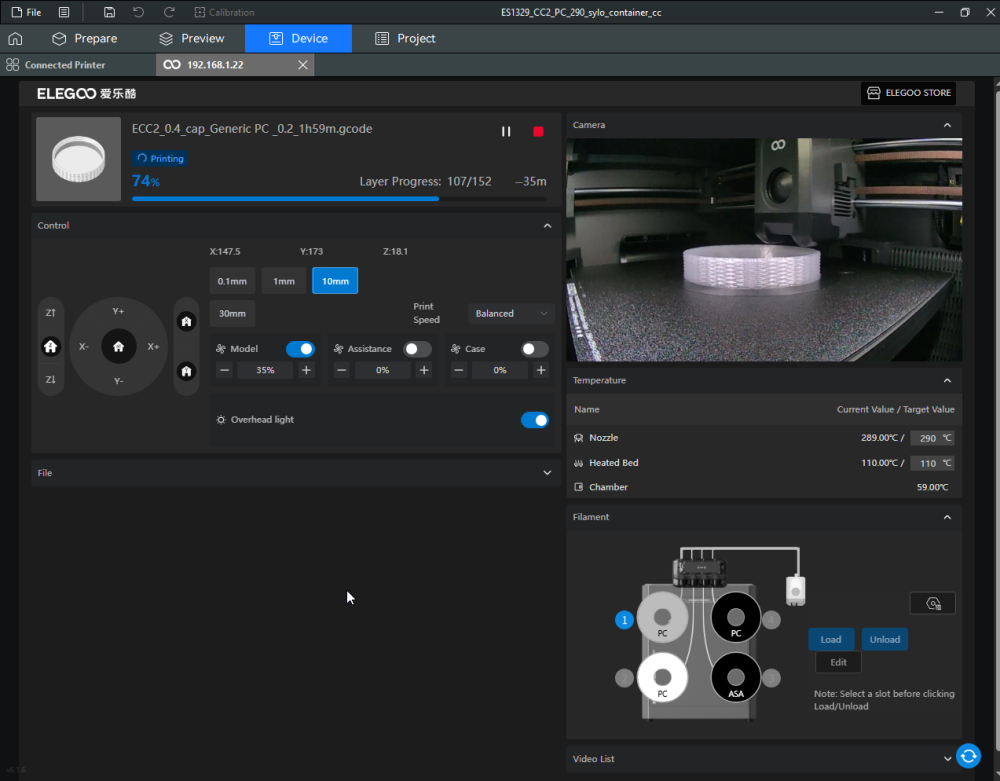
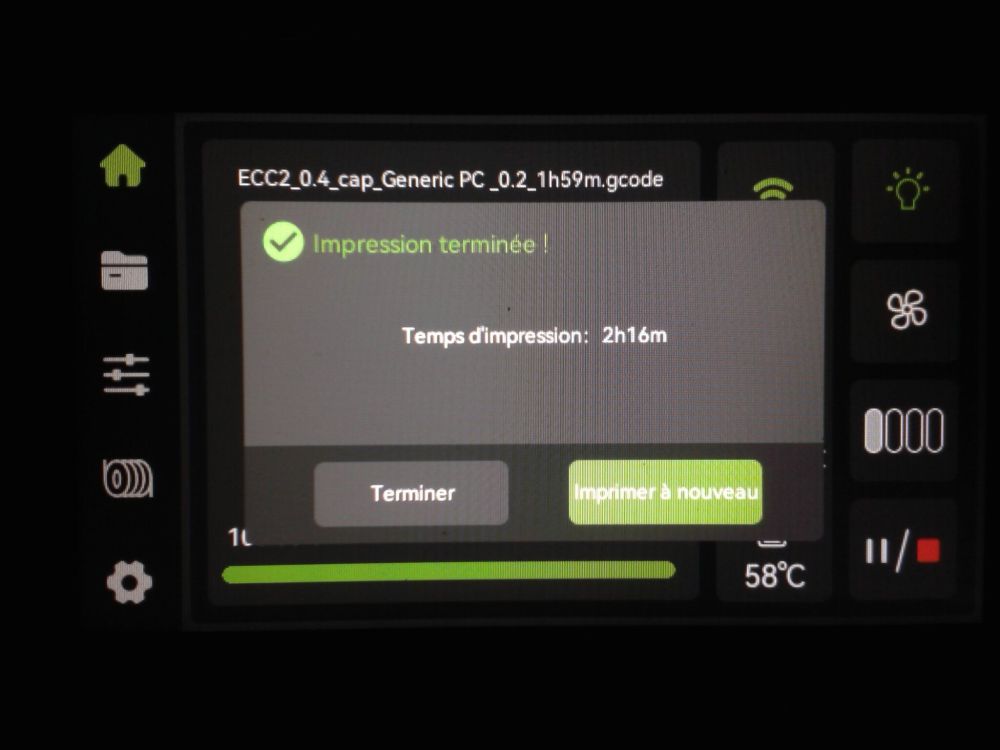
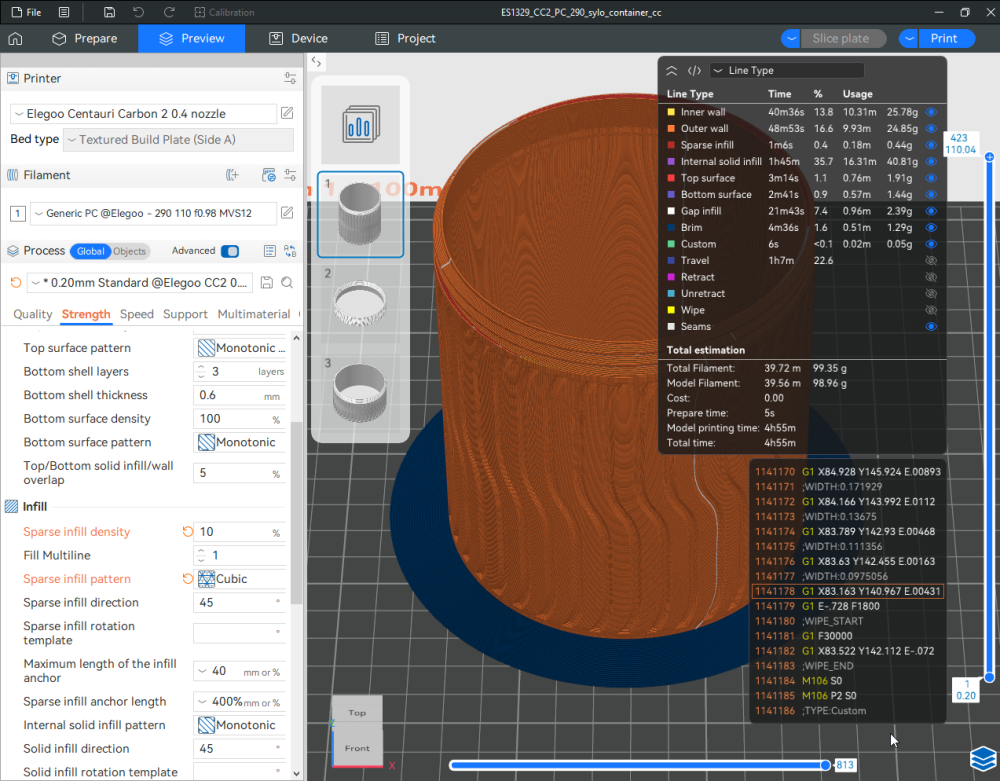
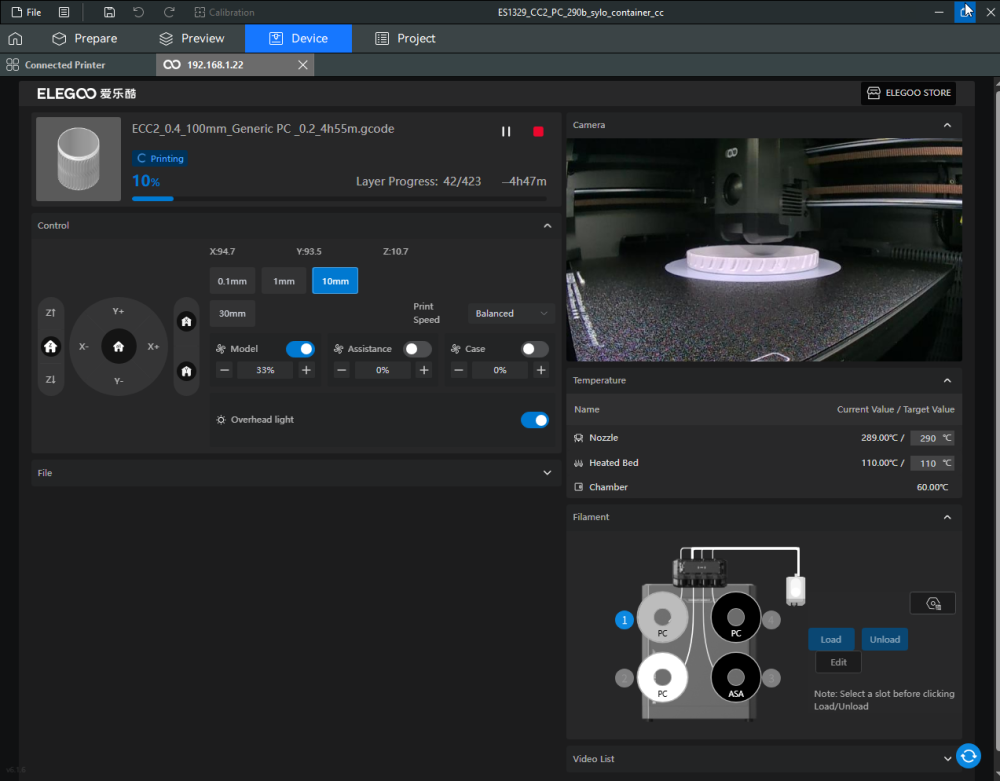
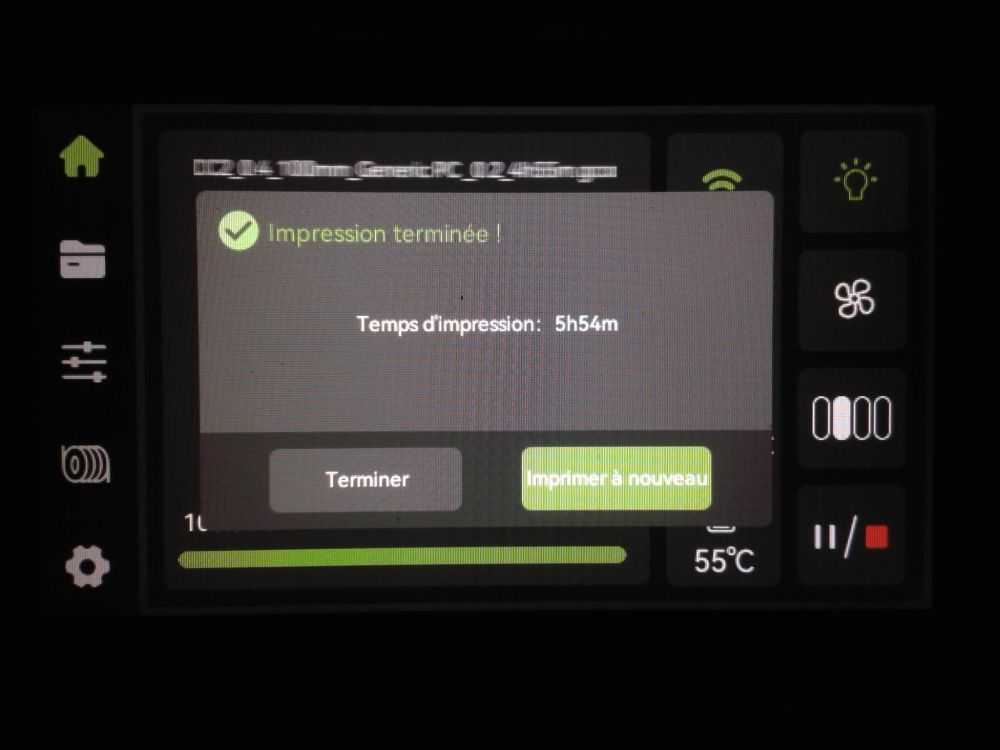
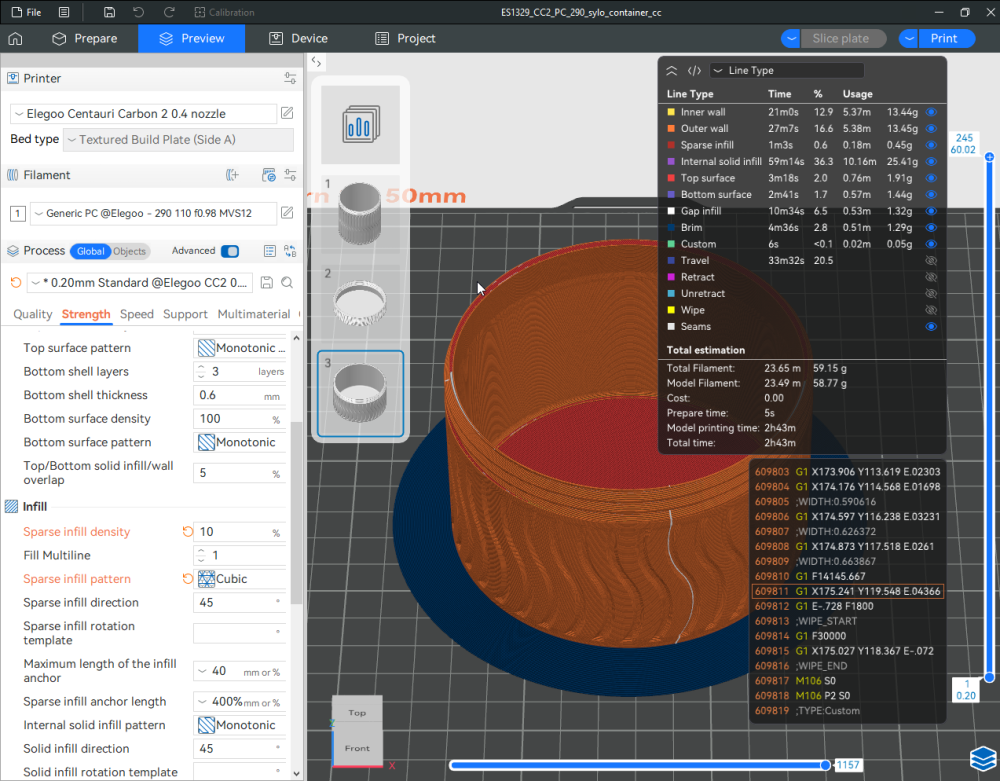
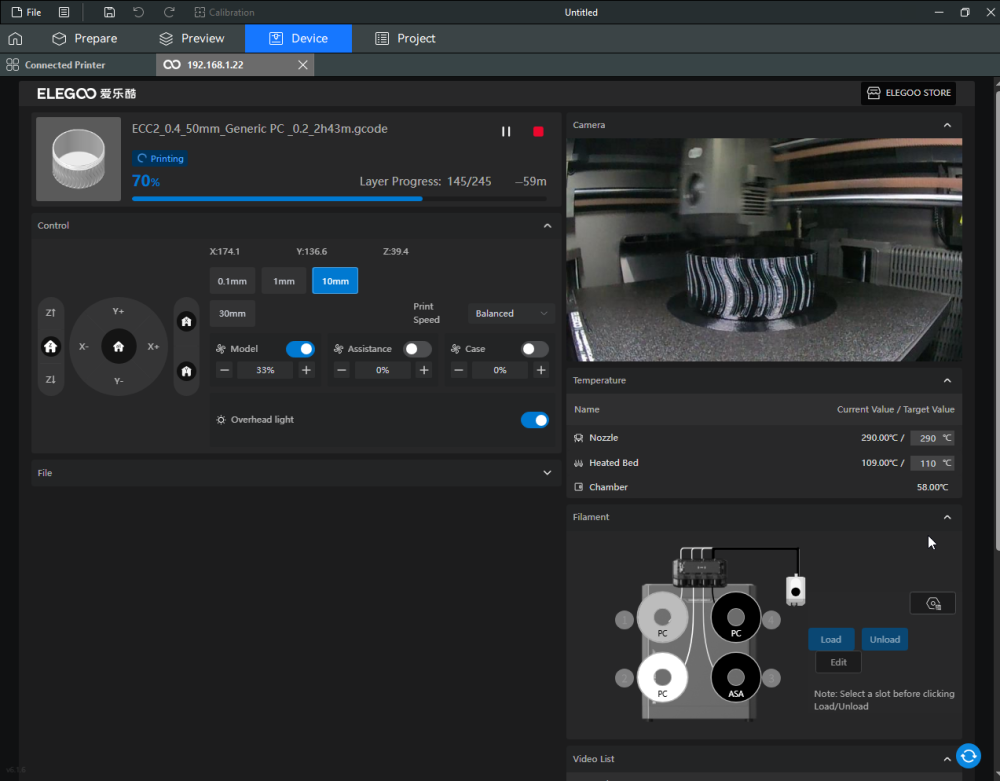
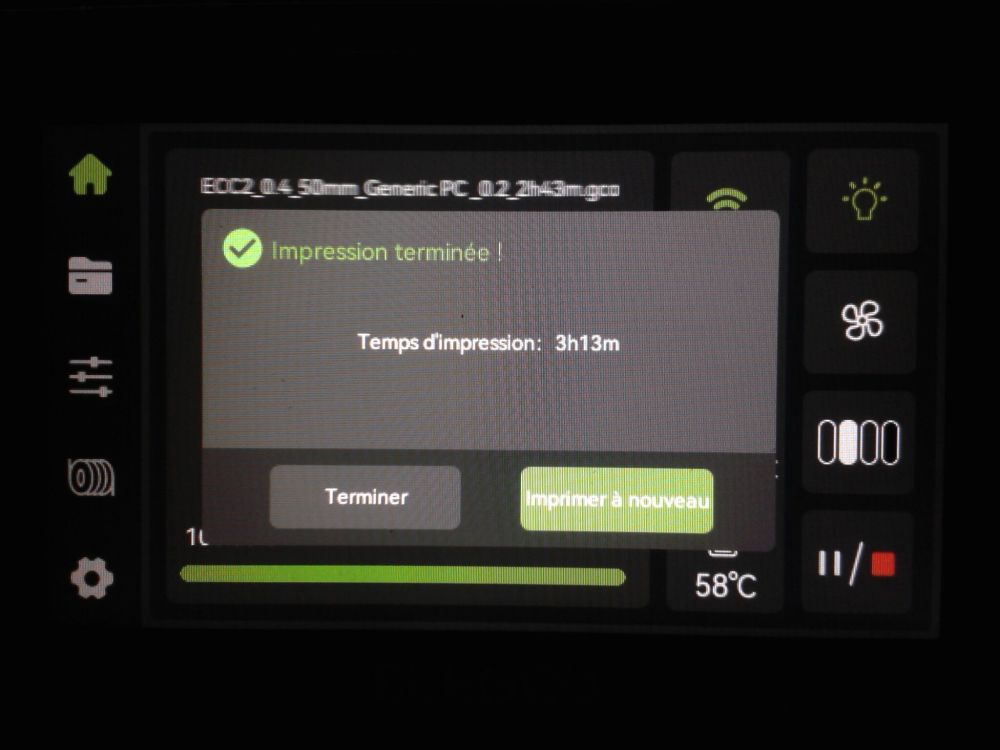
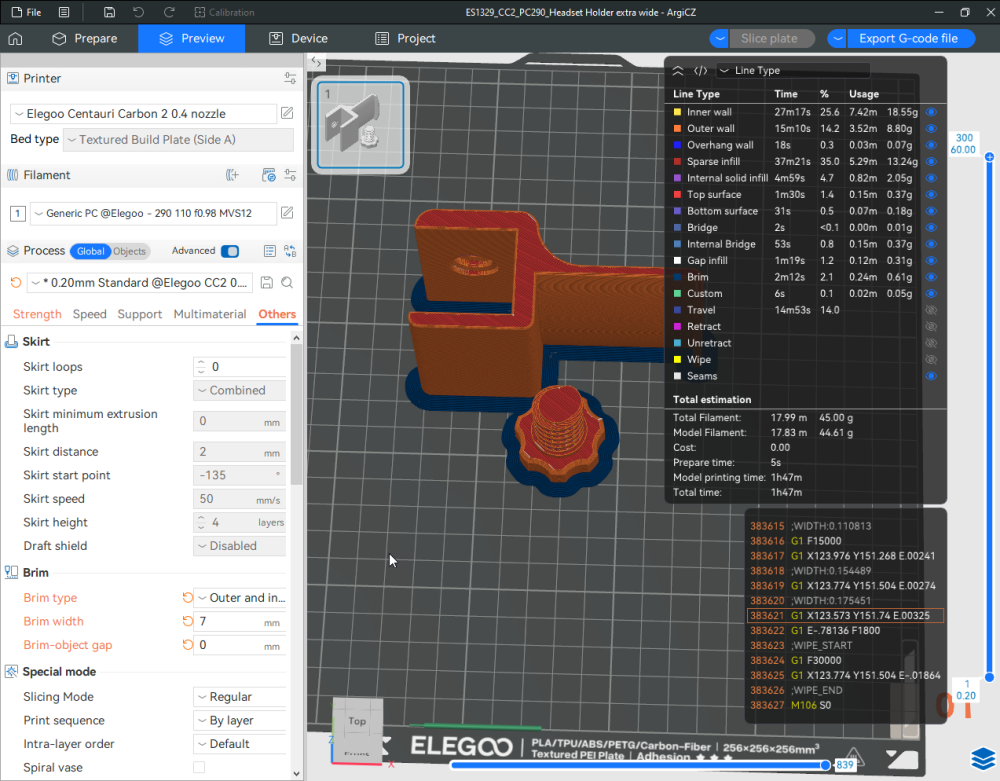
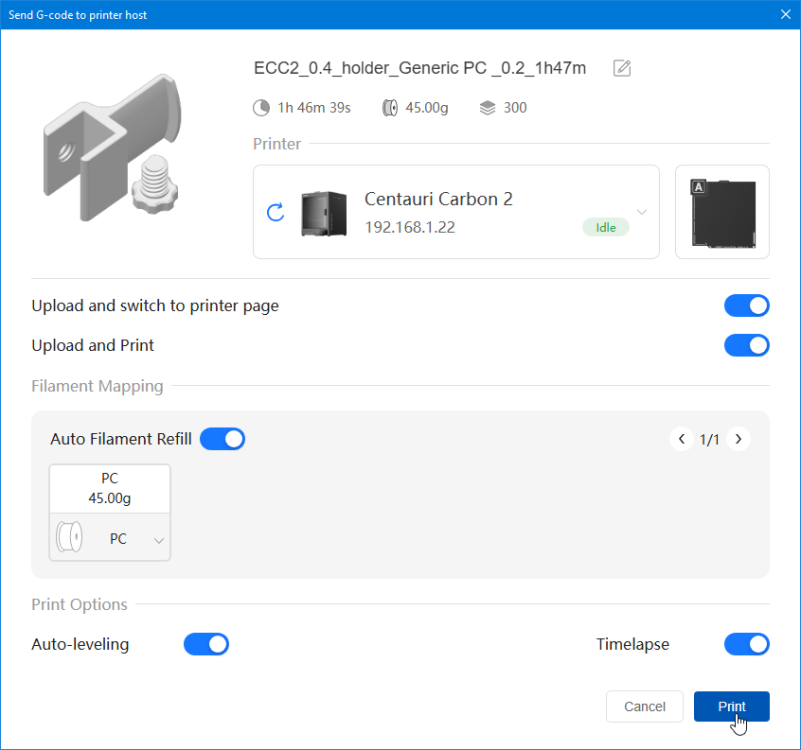
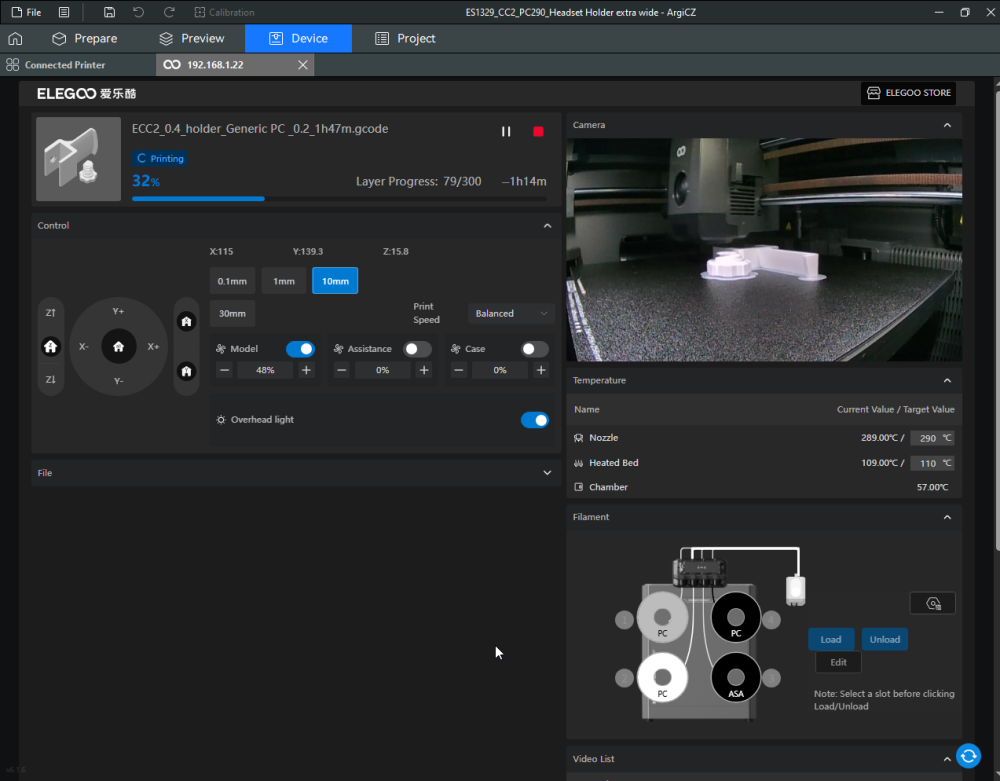
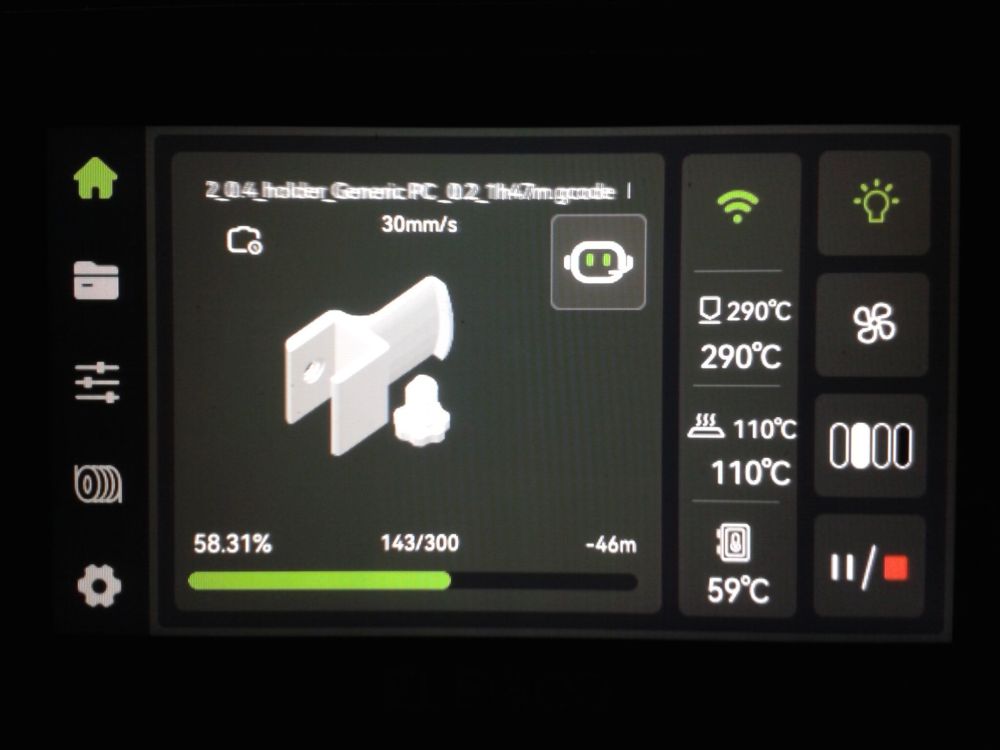
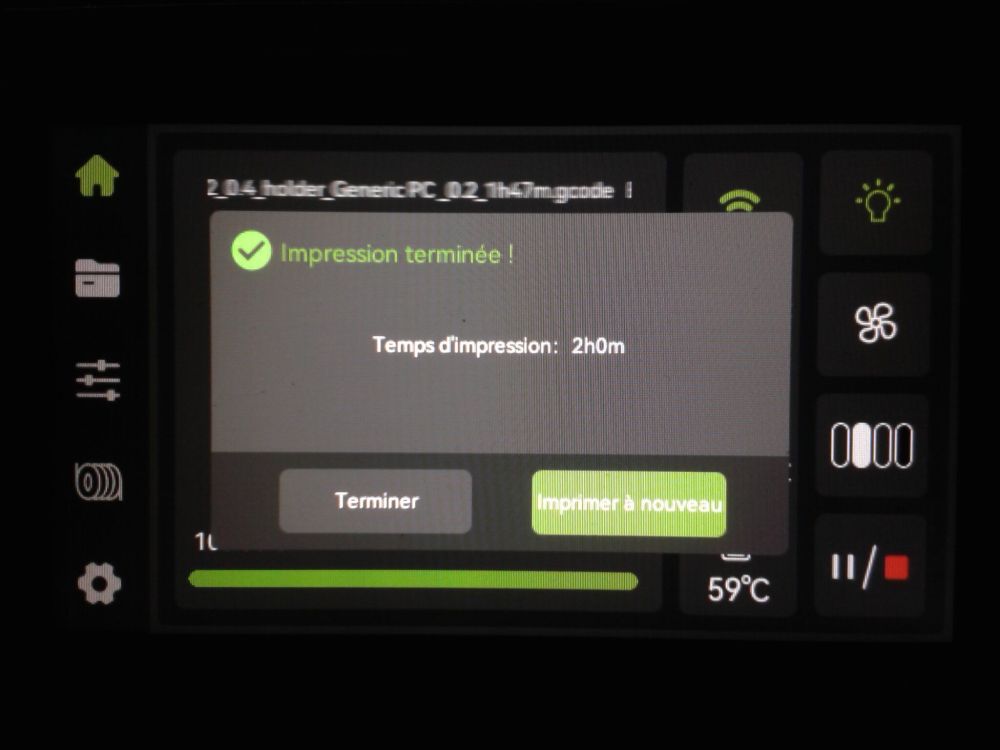
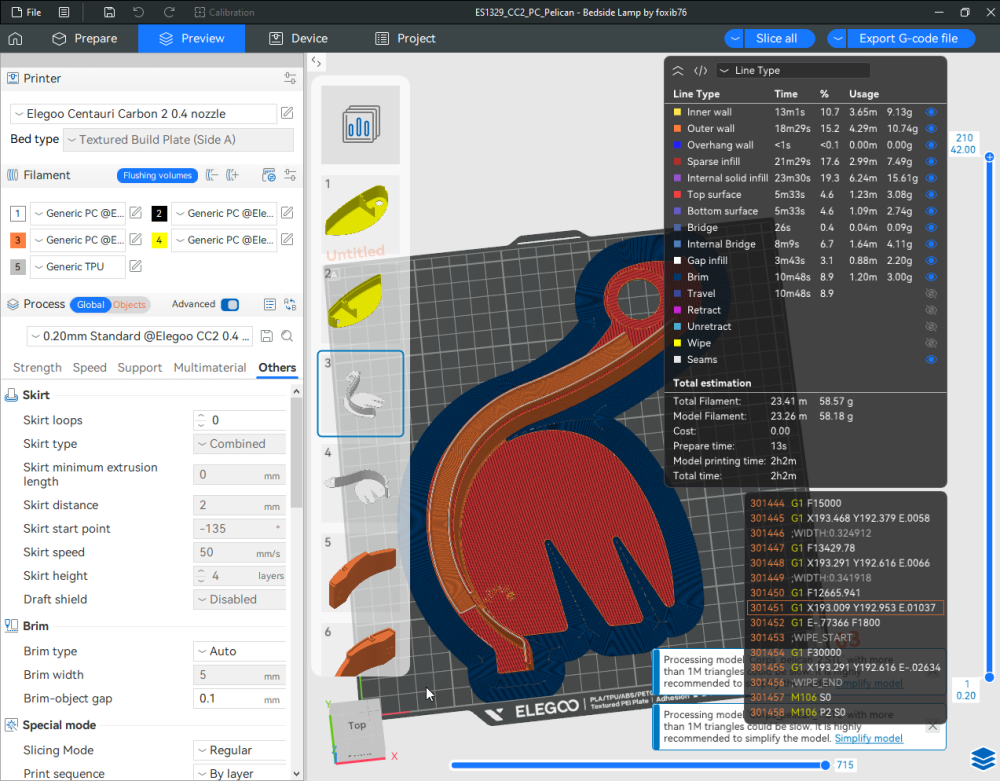
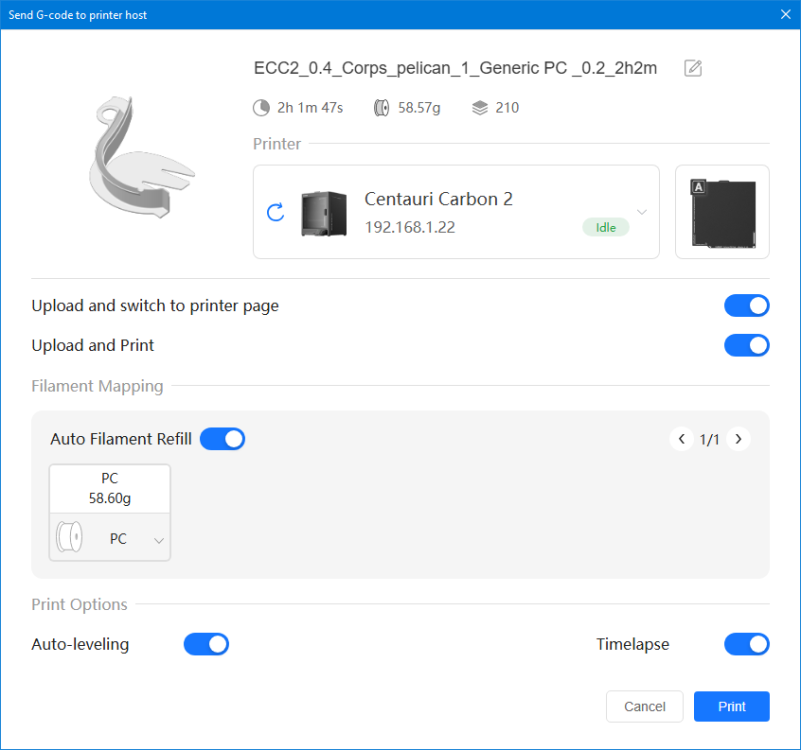
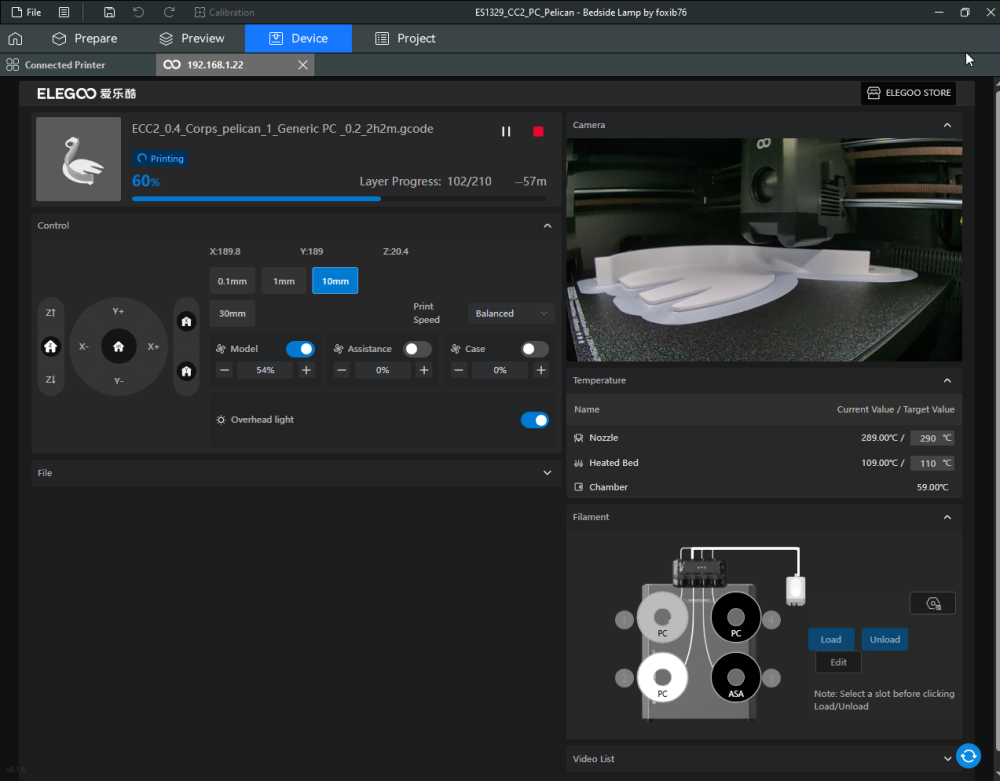
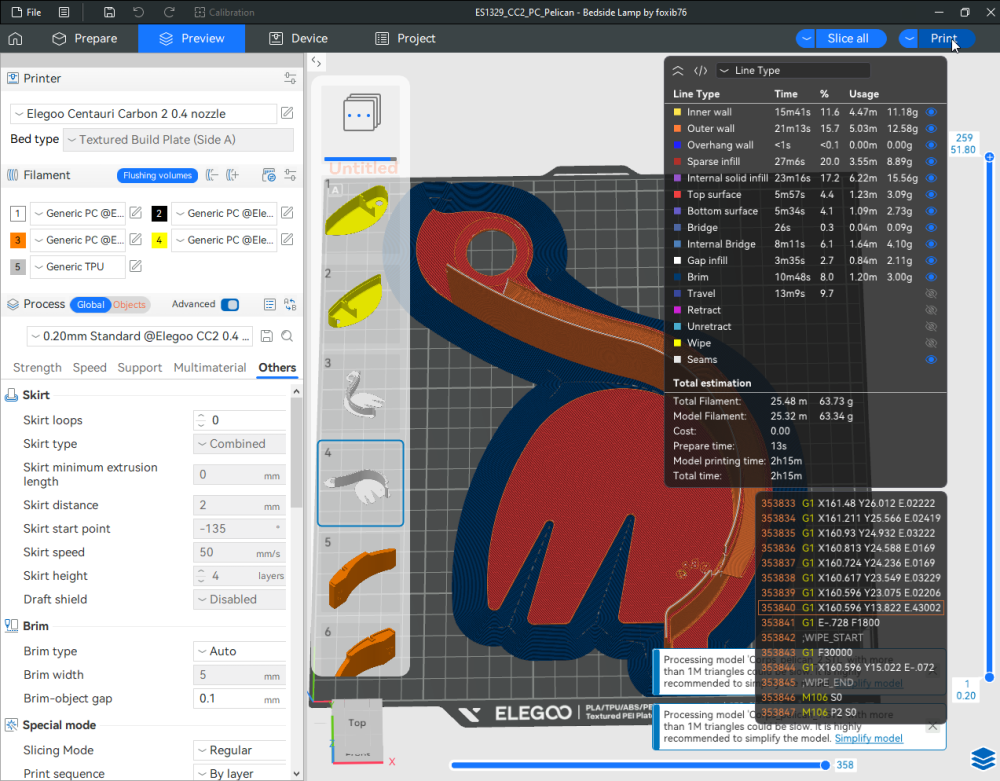
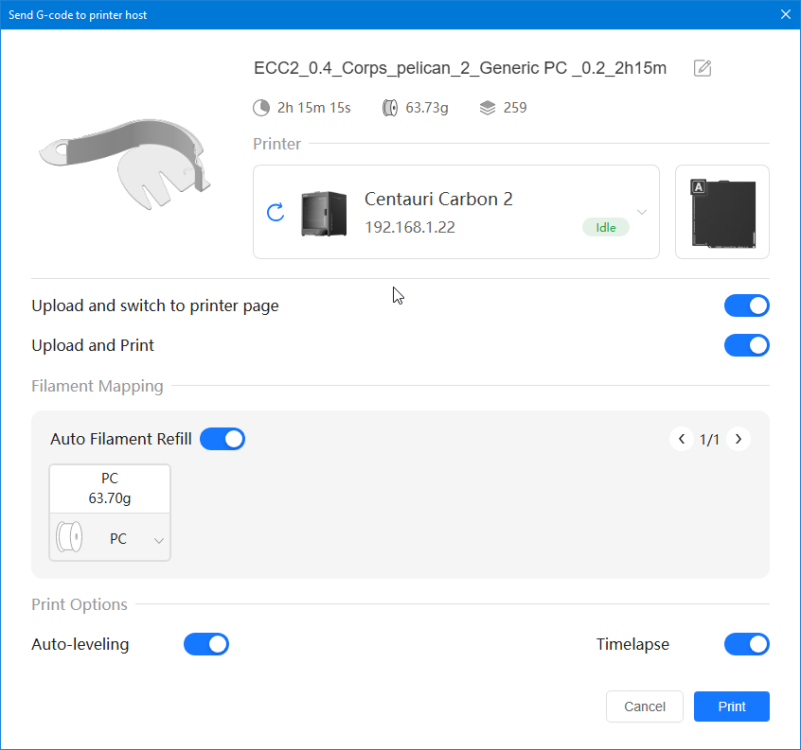
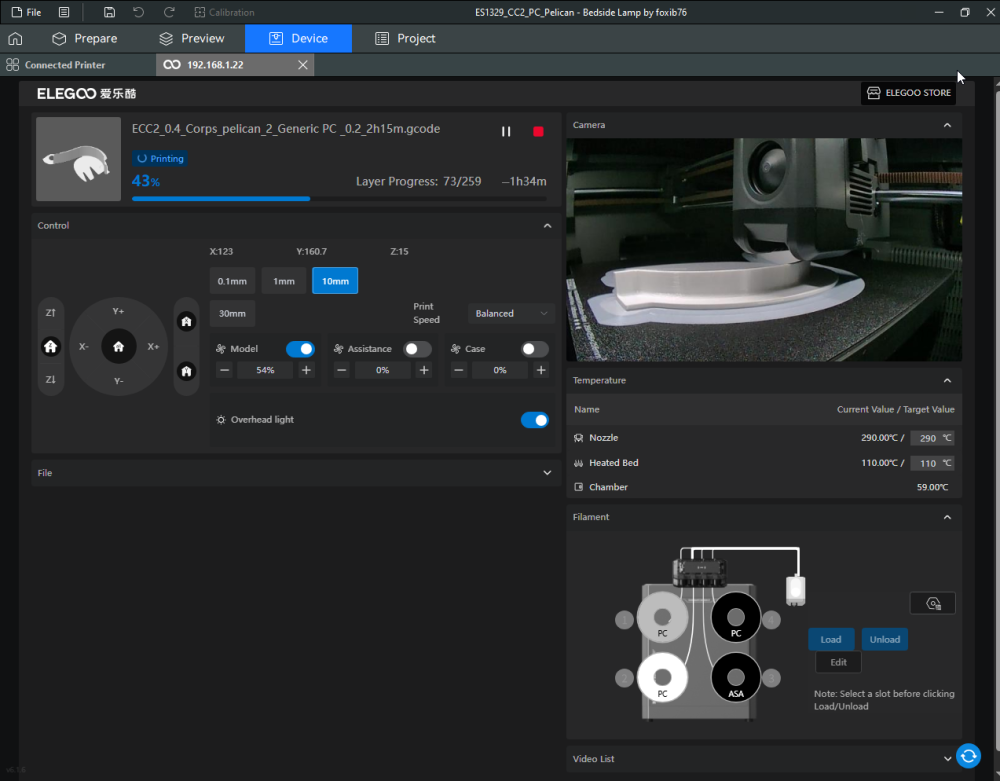
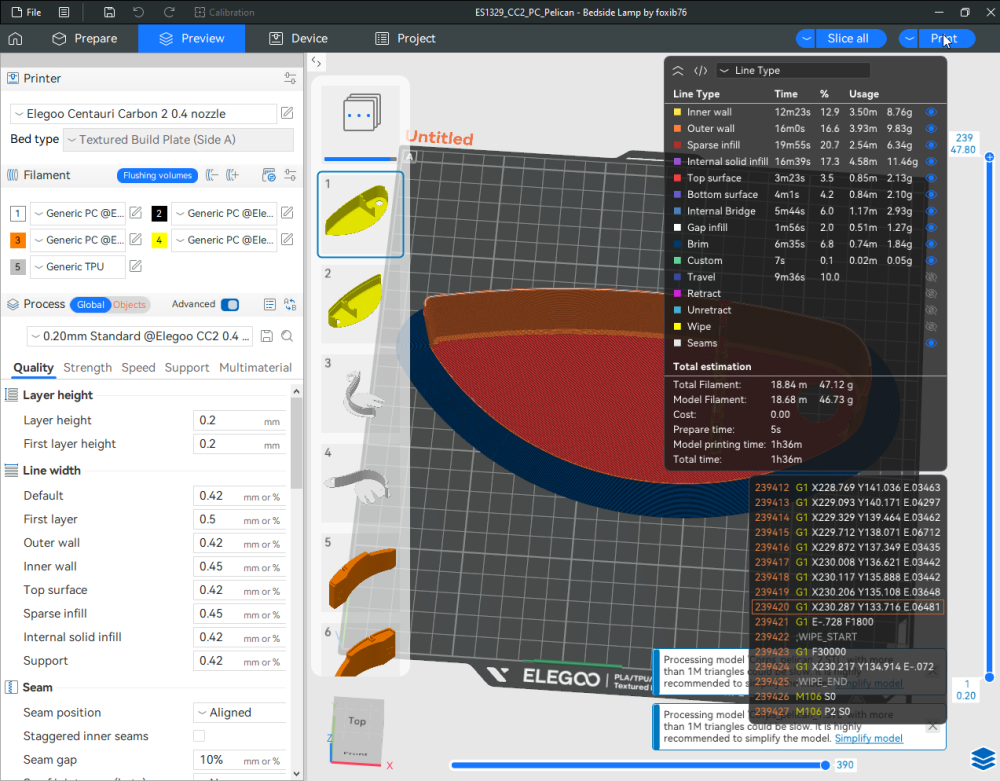
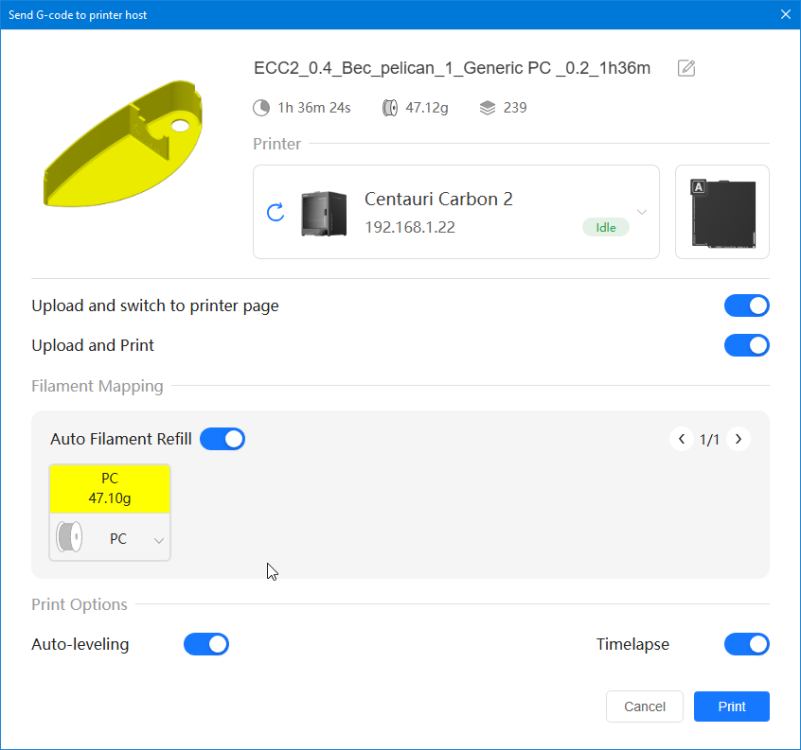
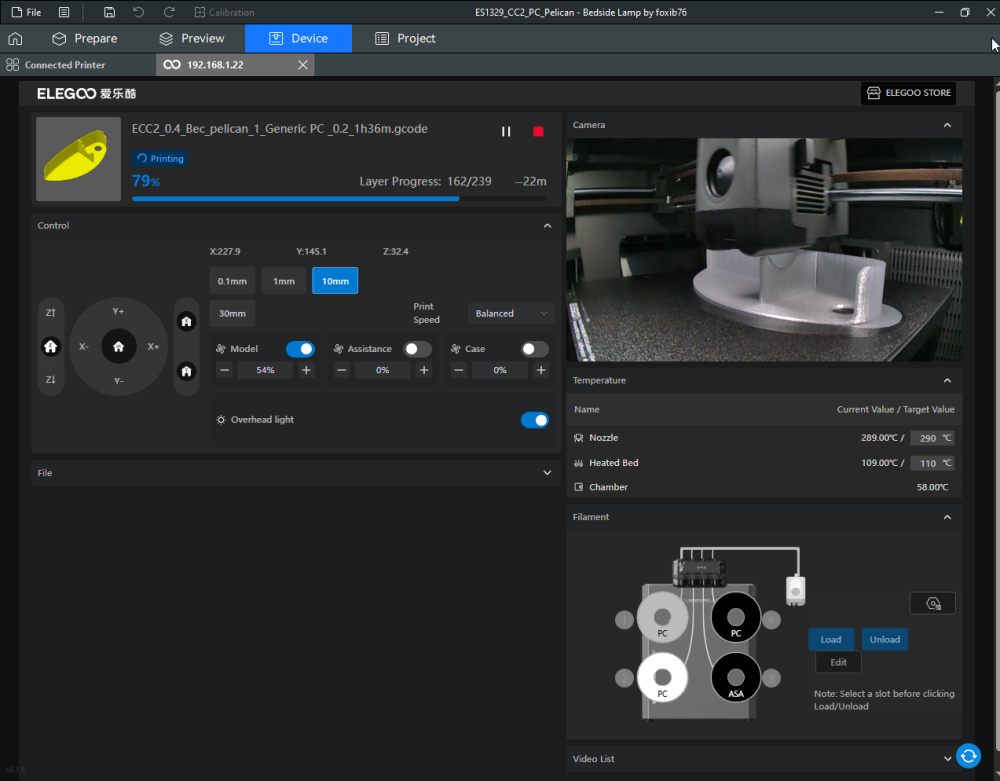
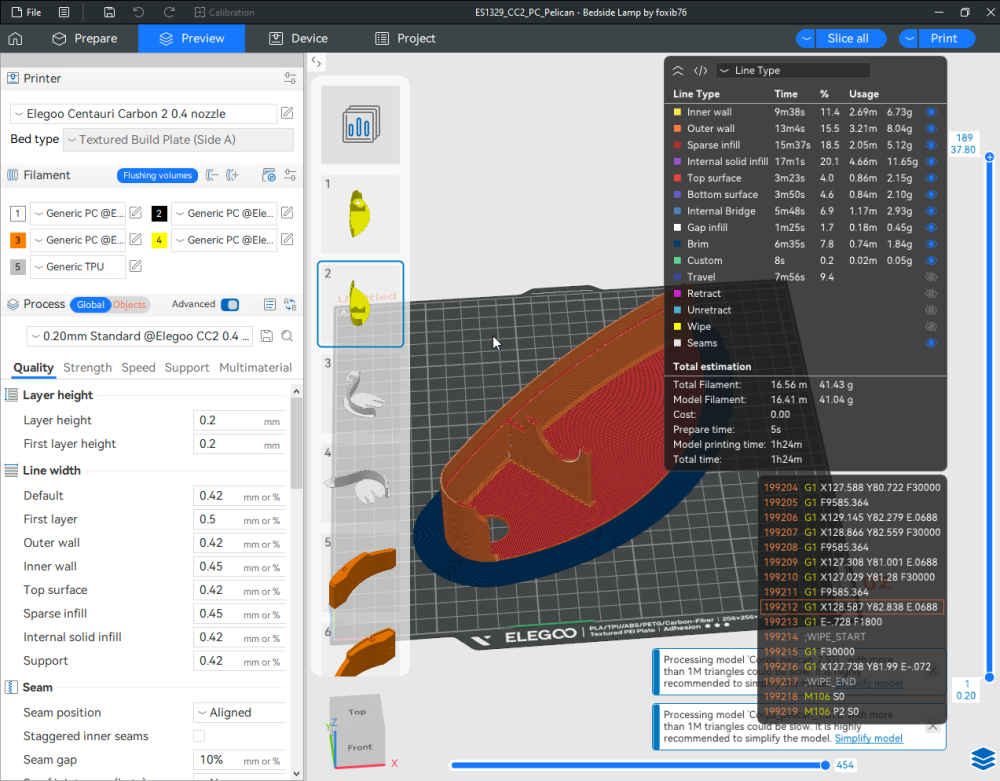
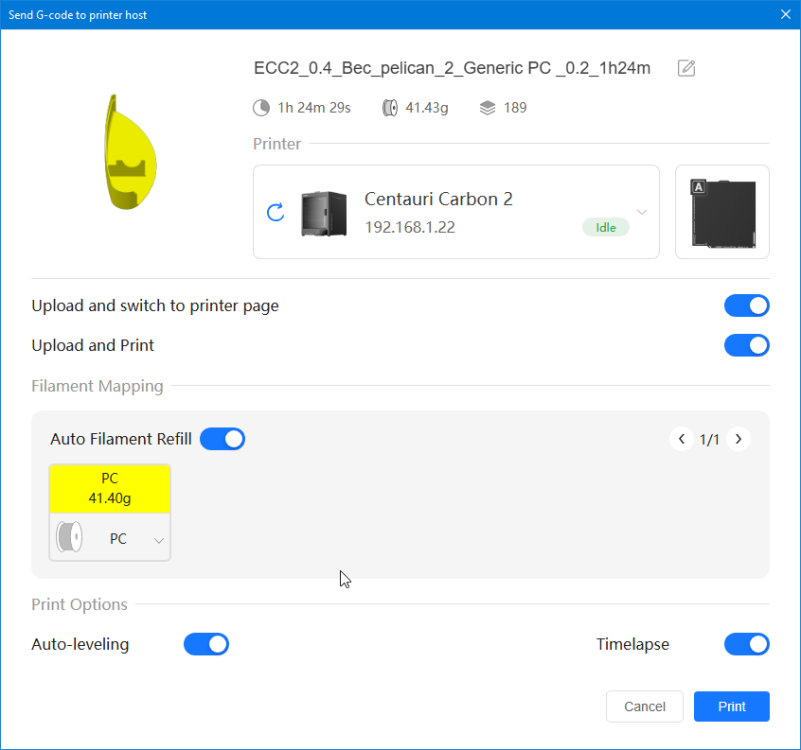
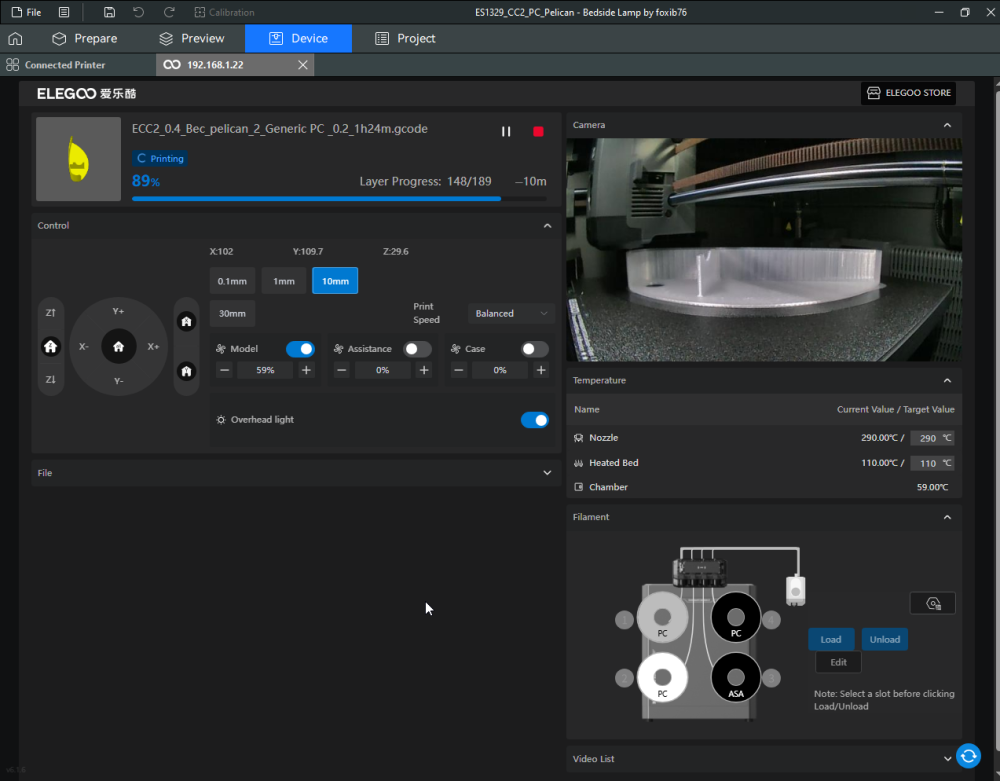
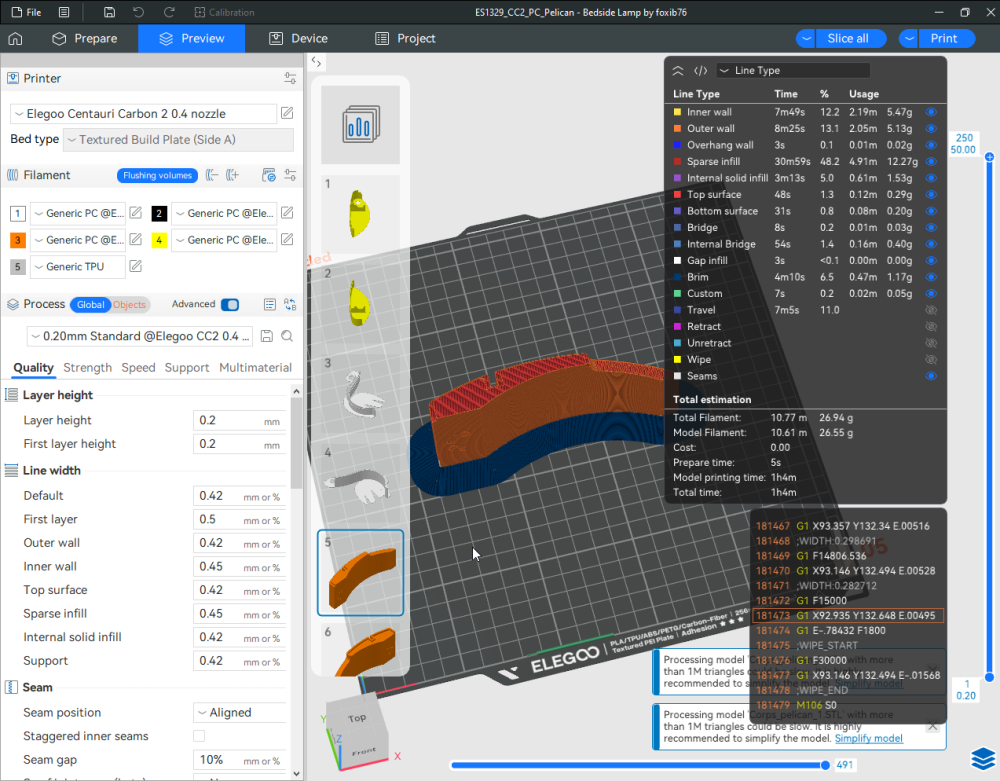
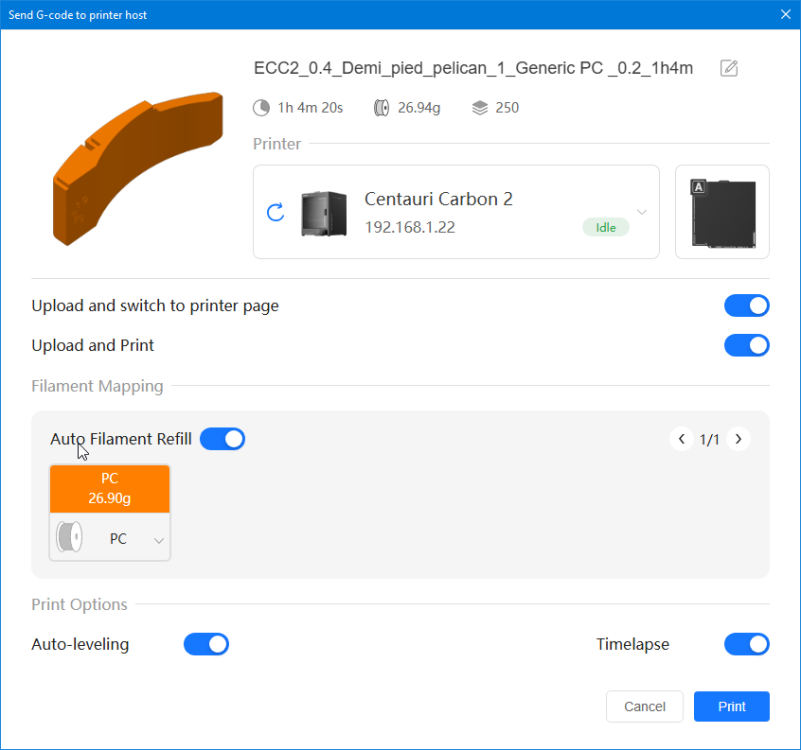
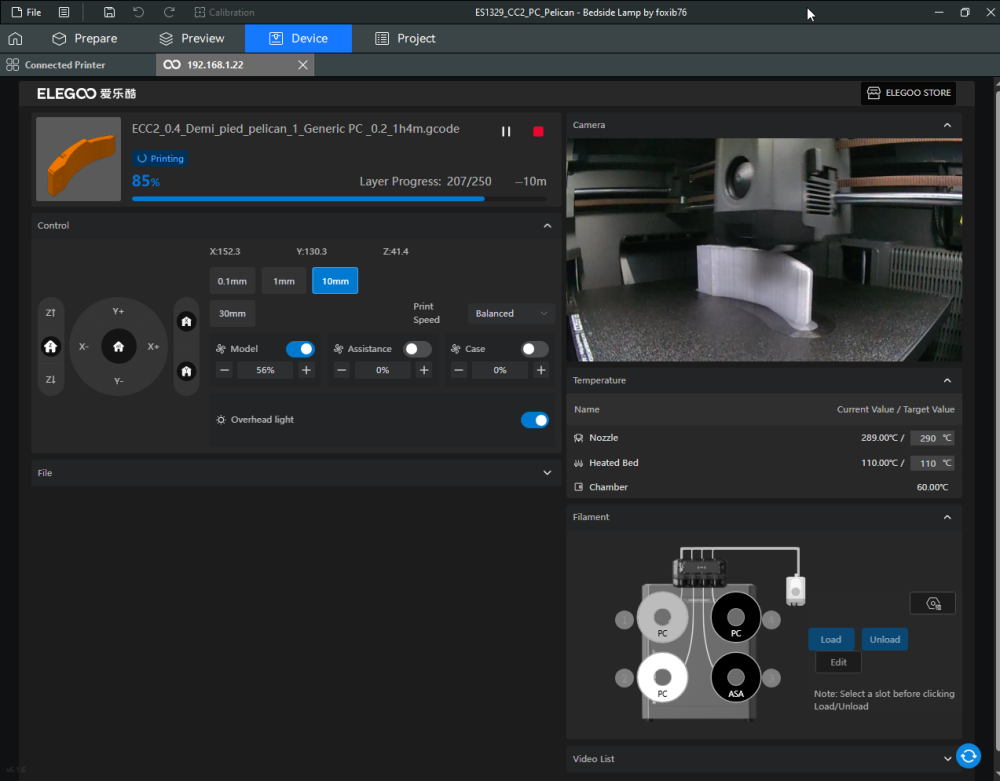
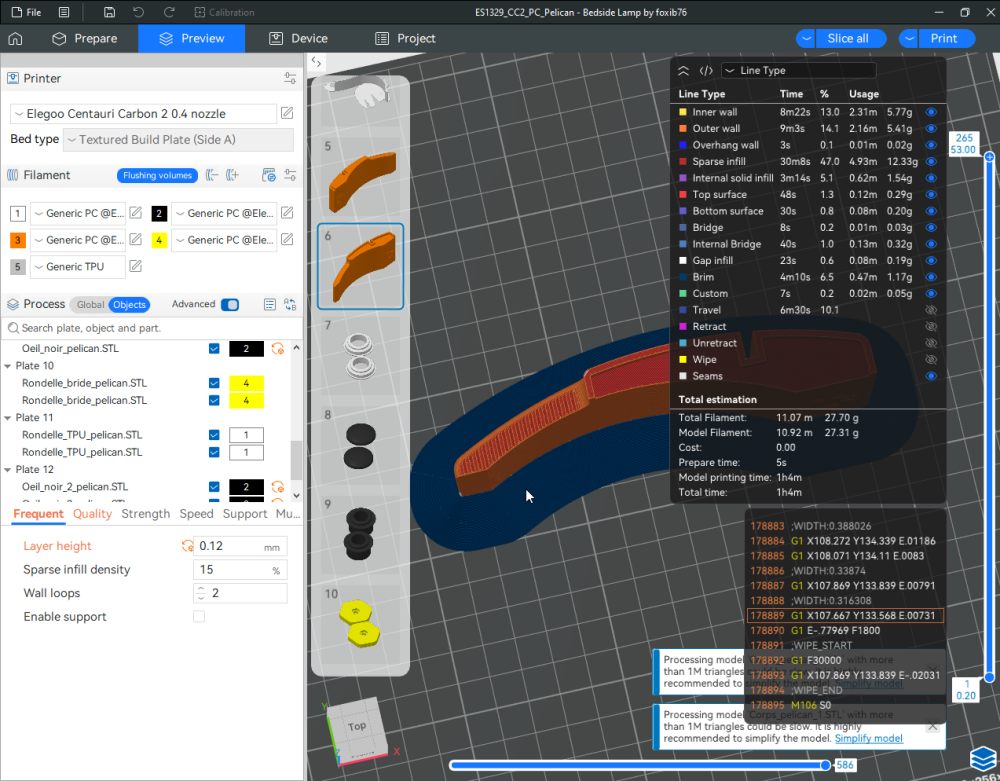
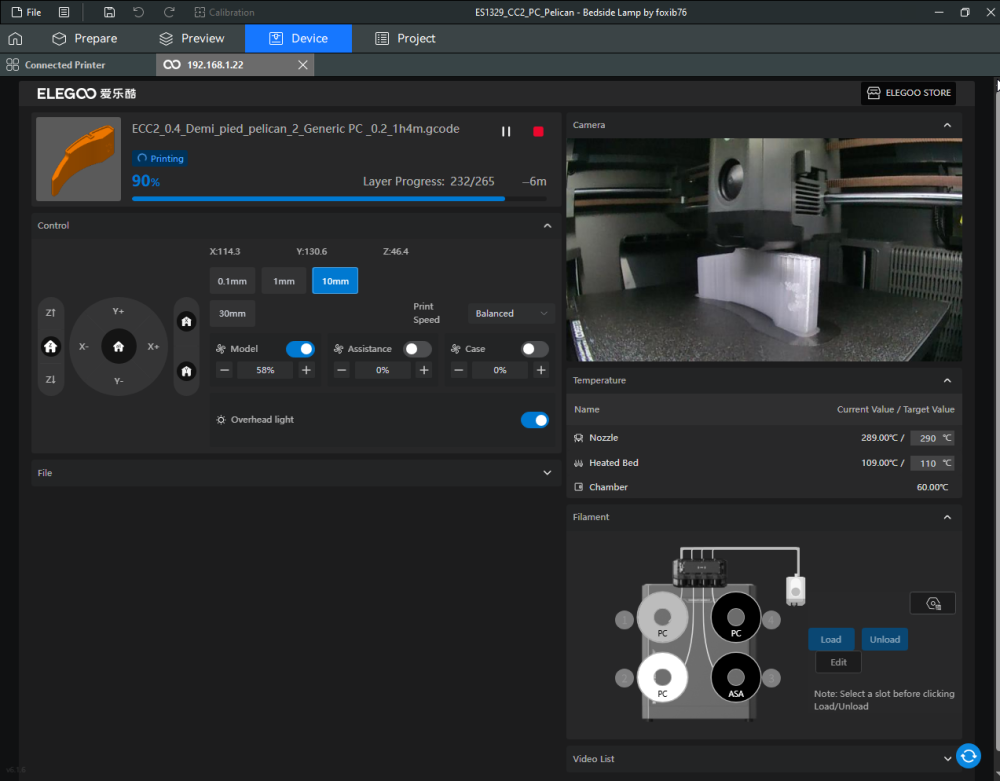
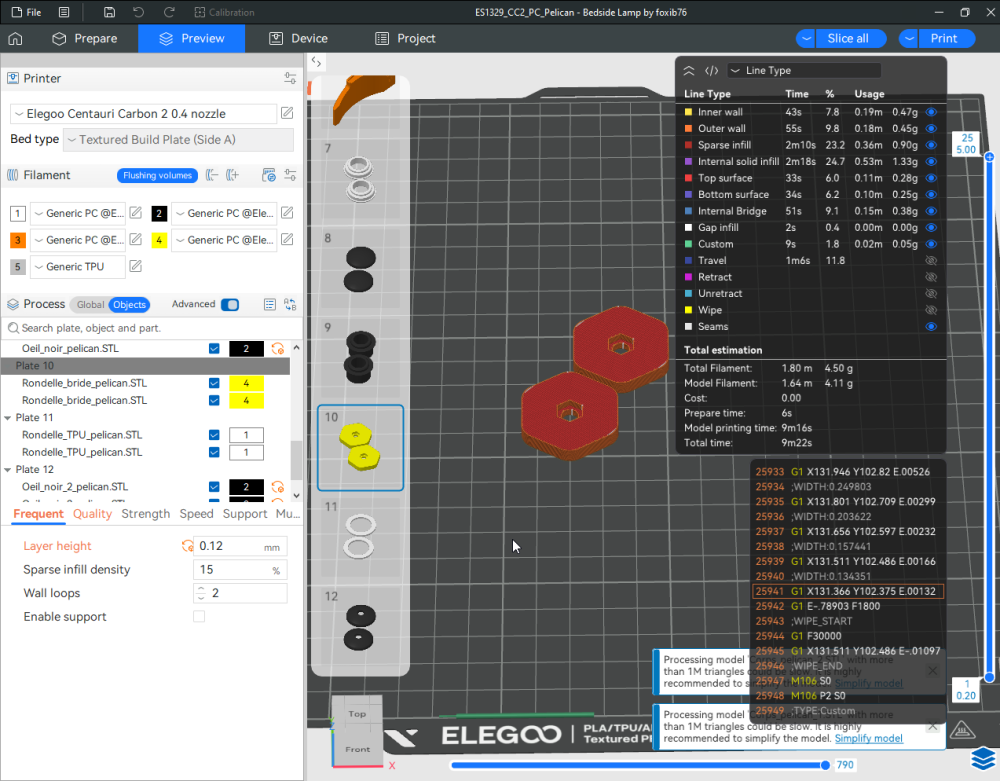
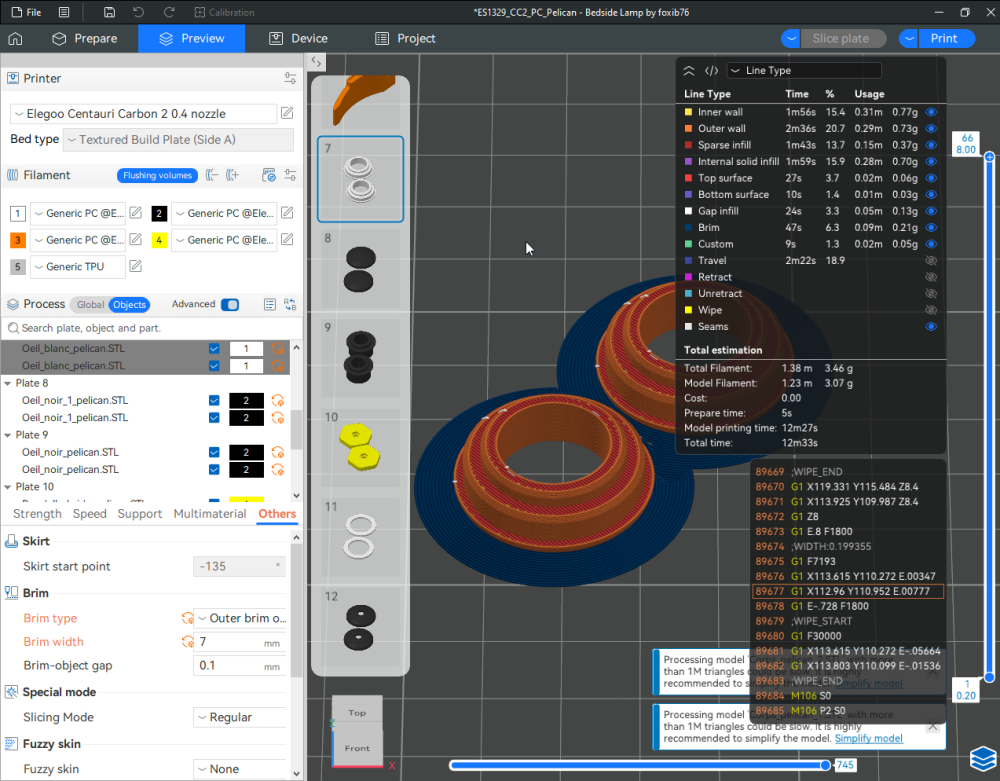
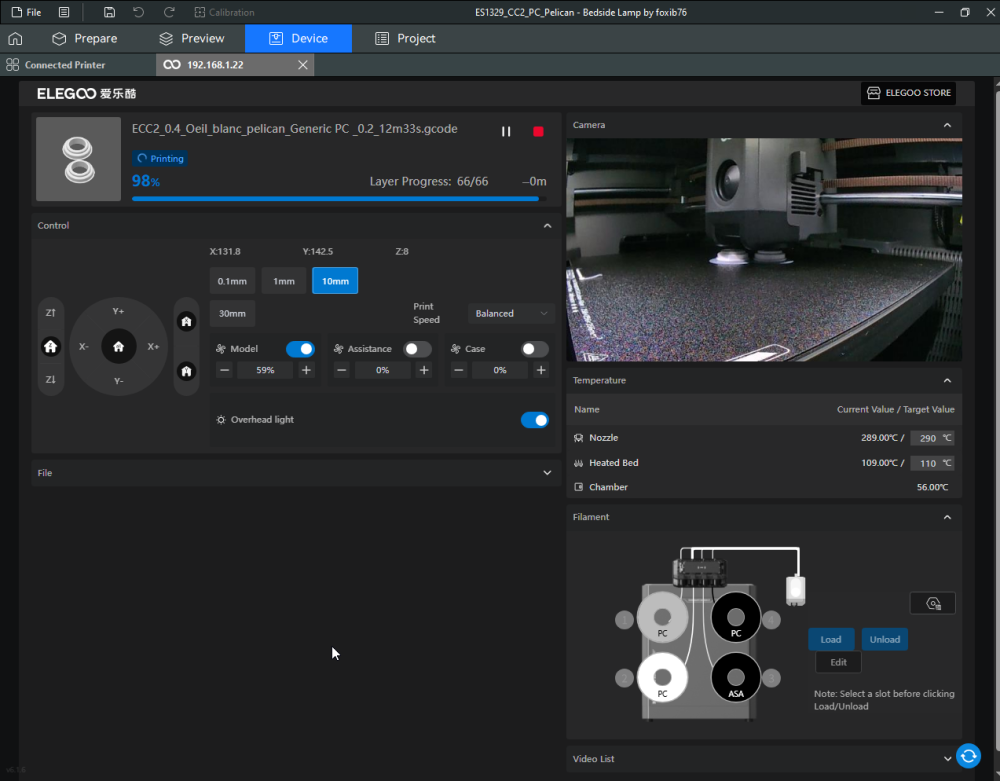
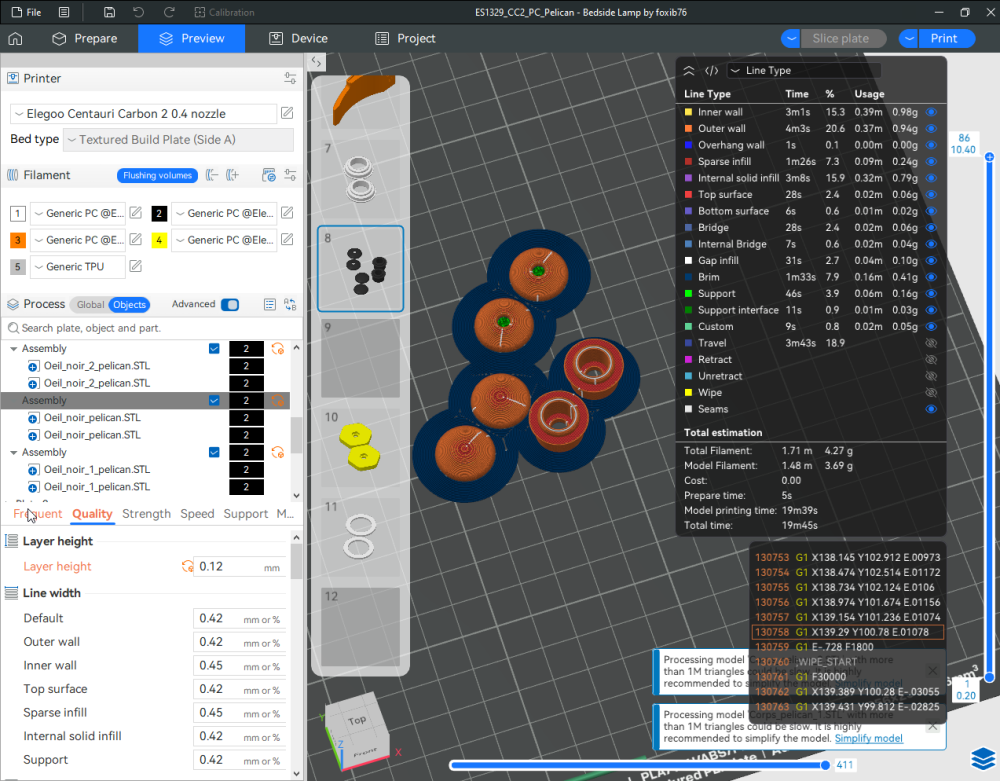
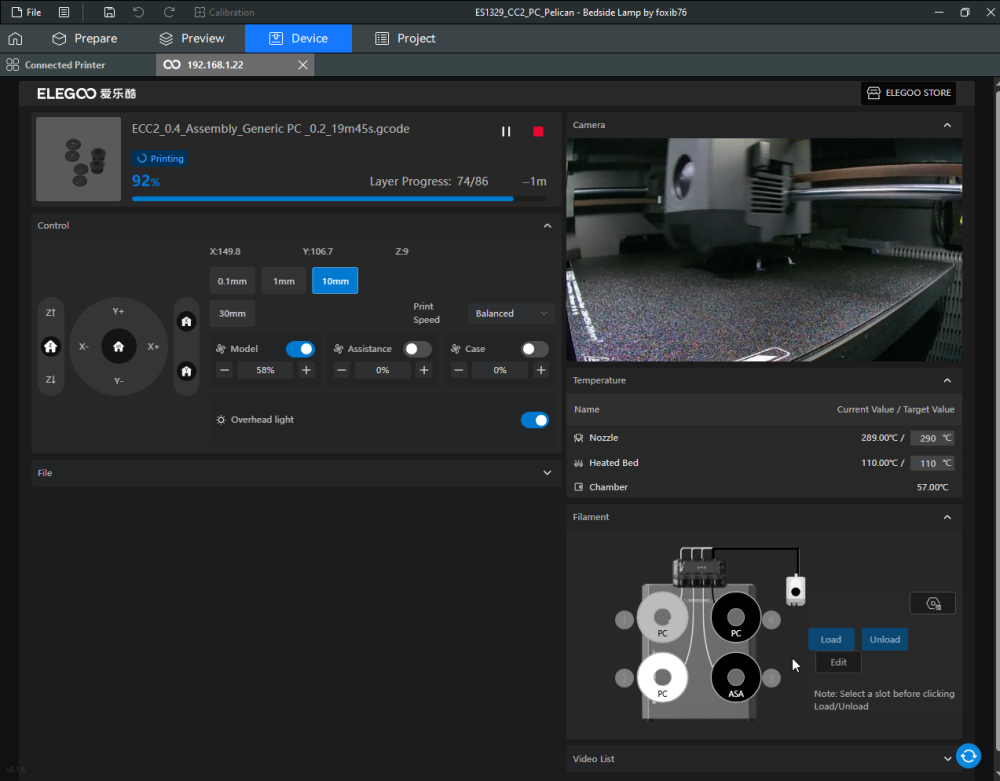
Autres impressions - PC Je n'avais pas vraiment d'expérience d'impressions avec des filaments de PC ( sauf un rapide essai avec du PCTG Vert ArianePlast fait lors de mon test de la Qidi Q1 Pro ) Et donc, je connais encore mal les prérequis et points importants pour correctement imprimer des filaments PC. Filaments utilisés pour ses impressions PC White Anycubic PC Black Anycubic PC Translucent White Anycubic Je me suis basé sur les spécifications du constructeur des filaments PC utilisés ( https://store.anycubic.com/products/pc-filament > buse 270-290°C, plateau 100-120°C, MVS 12 mm³/s, sécher la bobine avant utilisation 8-12 h à 80°C ) Je ne sais pas s'il y a des, ou quelles sont les, températures recommandées pour l'enceinte lors de l'impression de ce filament PC. Je suis partie du principe que pour limiter le gauchissement ou "warping", il fallait chercher à avoir dans l'enceinte la plus haute température que je pouvais obtenir dans la pièce à ~17°C où j'utilisais cette machine. Et j'ai donc grossièrement isolé l'imprimante avec les mousses de transport de l'imprimante et en plaçant à touche-touche de l'imprimante le sécheur de filament Creality Space Pi utilisé pour sécher à 70°C (température maximum sur ce sécheur) la bobine de filament PC en cours d'impression. sylo • container - h3liØ https://www.nexprint.com/en/models/G2102568 Pour mon premier essai d'impression avec un de ces filaments PC, J'ai utilisé le profil filament "Generic PC @Elegoo" (buse 270°C, plateau 110°C, MVS 12 mm³/s, flow 0.98 %) de Elegoo Slicer v1.3.2.9. Comme j'utilisais un filament transparent, j'ai voulu voir si en réimprimant le même modèle avec les mêmes paramètres mais à 290°C au lieu de 270°C j'obtenais ou non une meilleure transparence. Donc là, j'ai utilisé le profil filament "Generic PC @Elegoo" modifié (buse 290°C au lieu de 270°C, plateau 110°C, MVS 12 mm³/s, flow 0.98 %) de Elegoo Slicer v1.3.2.9. Il ne semble pas y avoir de différence visible au niveau de la transparence entre l'impression à 270°C et l'impression à 290°C. Pour la suite j'ai continué d'utiliser le profil filament "Generic PC @Elegoo" modifié (buse 290°C au lieu de 270°C, plateau 110°C, MVS 12 mm³/s, flow 0.98 %) de Elegoo Slicer v1.3.2.9. Les couvercles précédemment imprimés se vissent et se dévissent correctement de ces corps de boîte. Headset Holder extra wide - ArgiCZ https://www.nexprint.com/en/models/G8498722 Pelican - Lampe de chevet _ Pelican - Bedside Lamp - foxib76 https://www.thingiverse.com/thing:7275002 ( Merci à @Den76 pour ce modèle. Cf https://www.lesimprimantes3d.fr/forum/topic/64257-lampe-toucan/#findComment-658969 ) (J'ai plusieurs fois modifié les placements et orientations sur les plateaux et quelques paramètres de tranchage de certain objet du projet Elegoo Slicer que j'ai fait pour faire ses impressions… ce qui explique les possibles différences sur les captures d'écran d'Elegoo Slicer.) // On peut noter un léger gauchissement car la bordure d'impression commence à se détacher du plateau sur certaines zones. // À posteriori j'aurais dû mettre des supports d'impression sur une petite zone de cet objet ... // Et, là encore, on peut noter un léger gauchissement car la bordure d'impression commence à se détacher du plateau sur certaines zones. // À posteriori j'aurais dû mettre des supports d'impression sur une petite zone de cet objet ... // Et, là encore, on peut noter un léger gauchissement car la bordure d'impression commence à se détacher du plateau sur certaines zones. ( // Premier essai d'impression de ce plateau raté car je n'avais pas mis de bordure d'impression et les objets imprimés se sont décollés du plateau en cours d'impression. ) ( Là en TPU, CANVAS déconnecté, hub filament 4-1 démonté, capot thermique plastique enlevé, pour alimenter directement la tête d'impression avec le filament TPU. ) On peut voir que j'ai oublié de mettre des supports d'impression pour certaines zones des pieds. Et que j'ai un léger "pillowing". // J'imprime certainement trop chaud pour ce filament. Les pontages (des yeux noirs, non percés, sans supports) ne sont pas bons // J'imprime certainement trop chaud pour ce filament. Je n'ai pas encore collé, même si certaines impressions semblent avoir légèrement gauchi a l'impression ou au refroidissement, tout semble s'assembler correctement et le collage devrait rattraper les différents gauchissements ...















































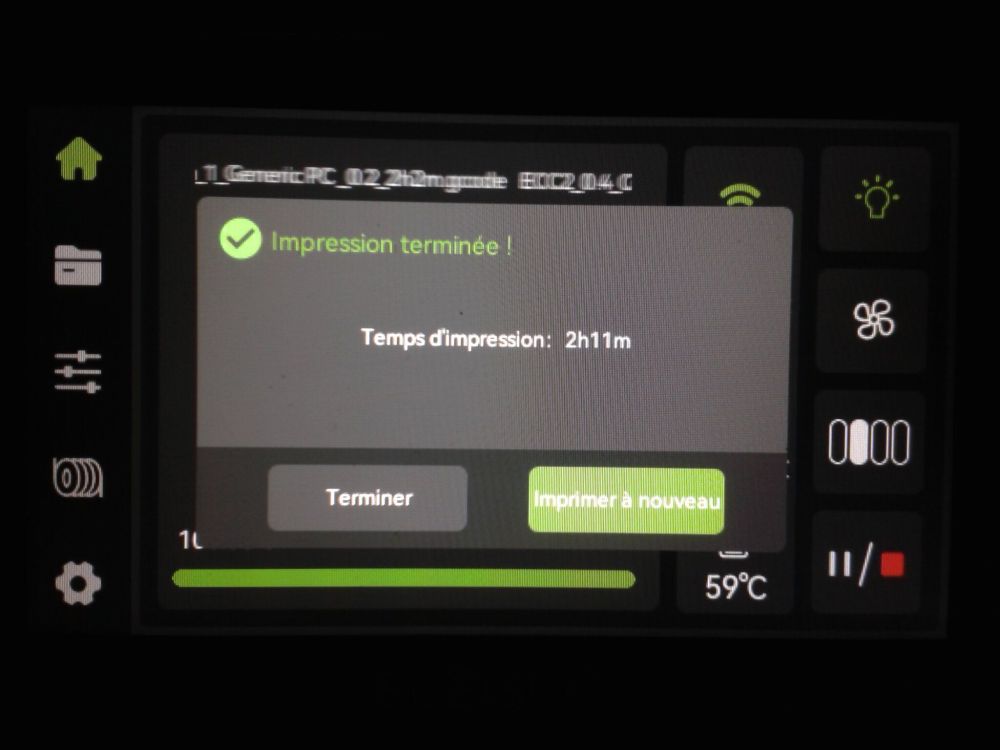


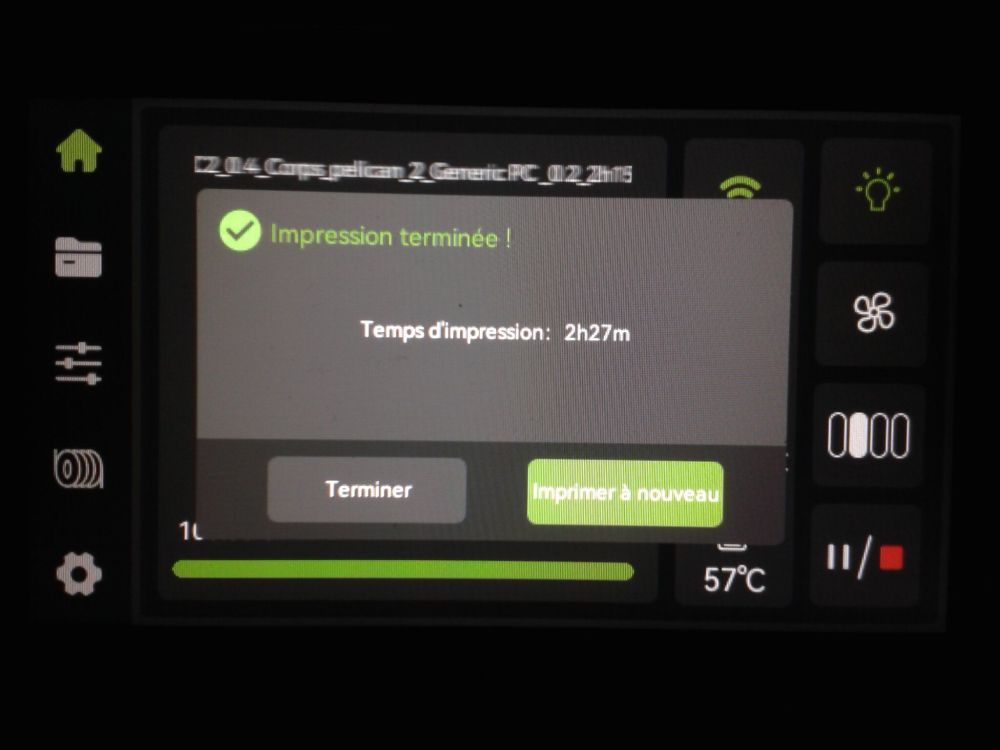


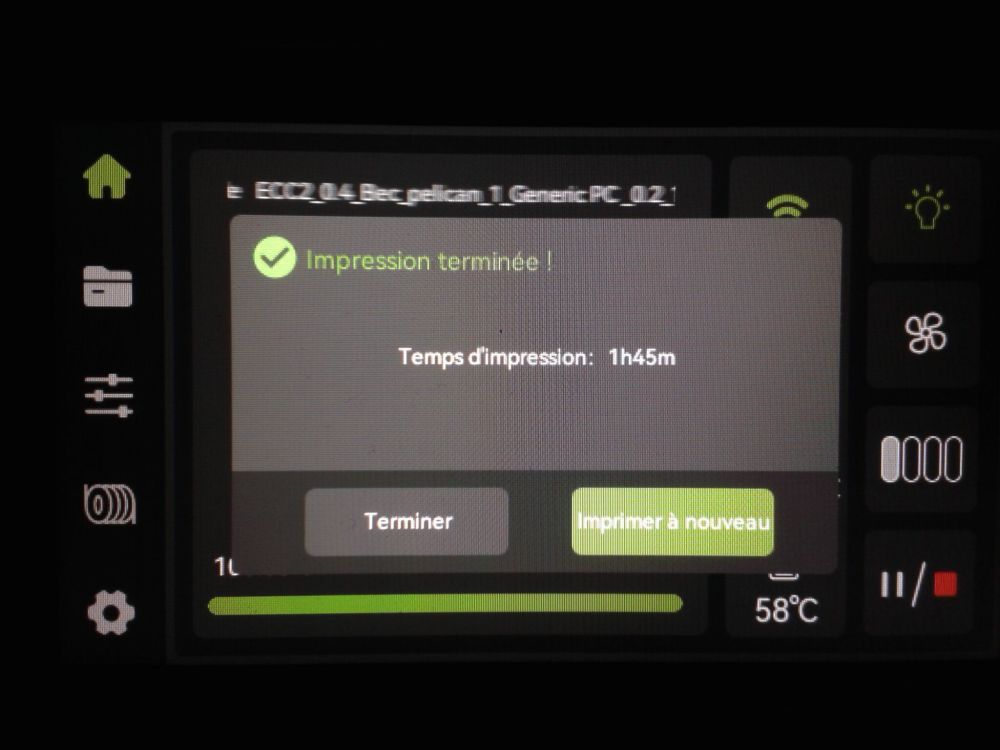



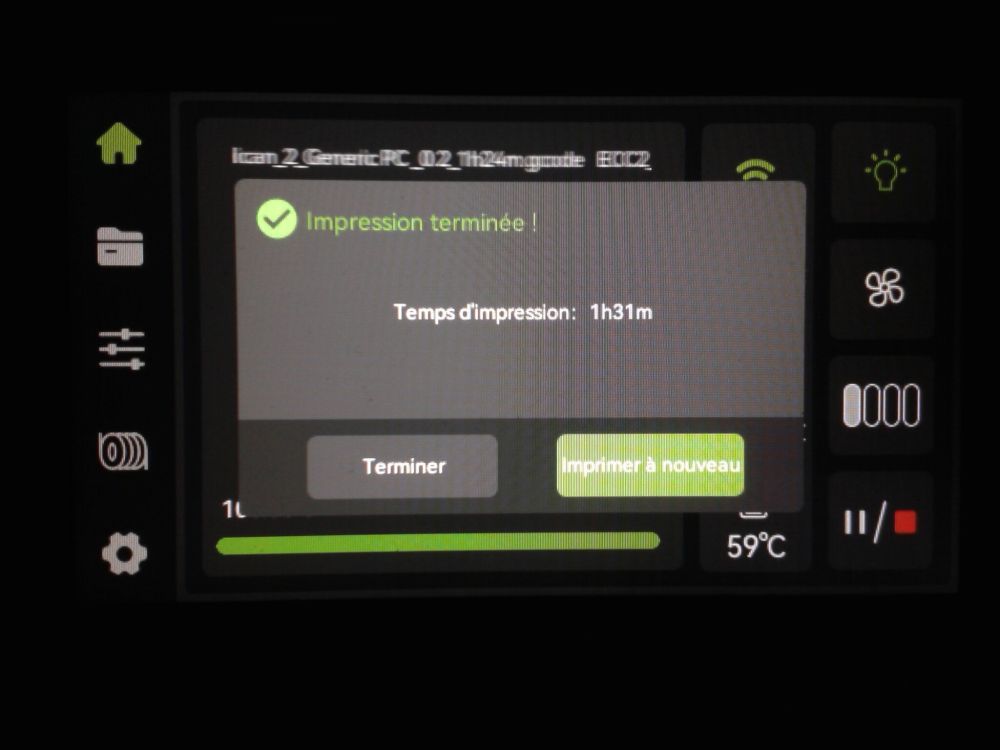






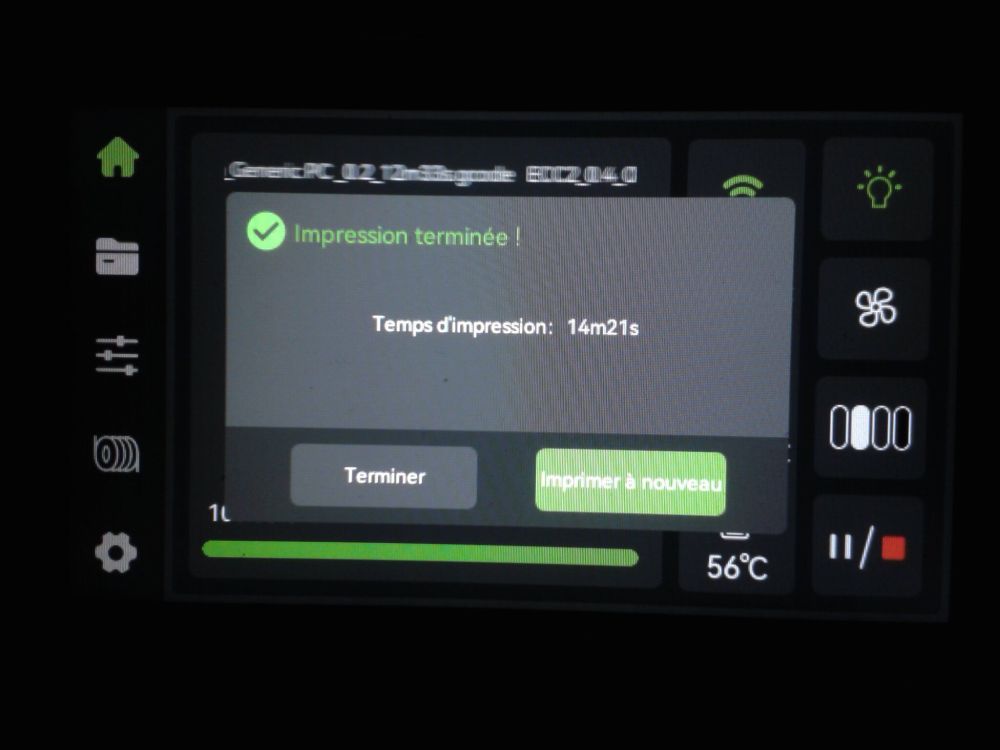


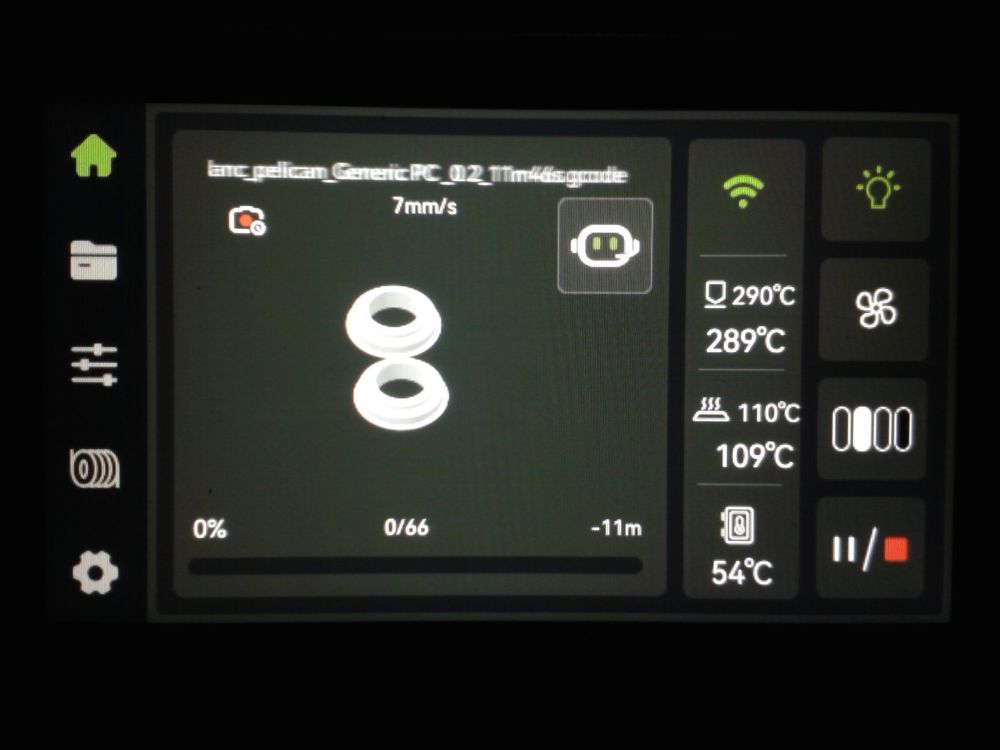


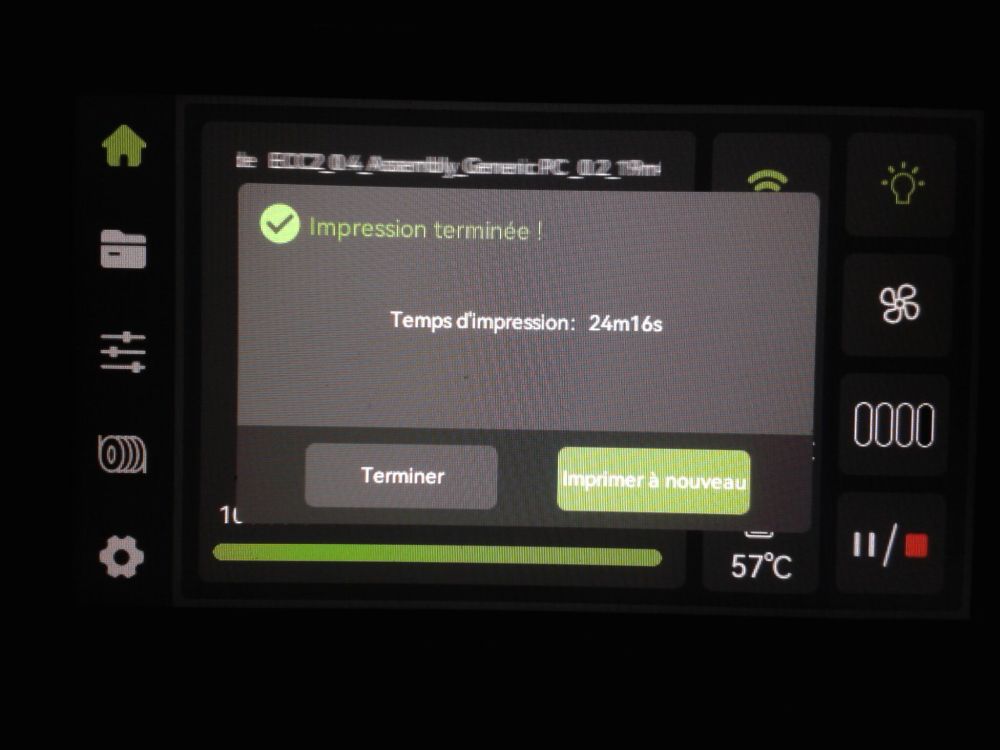


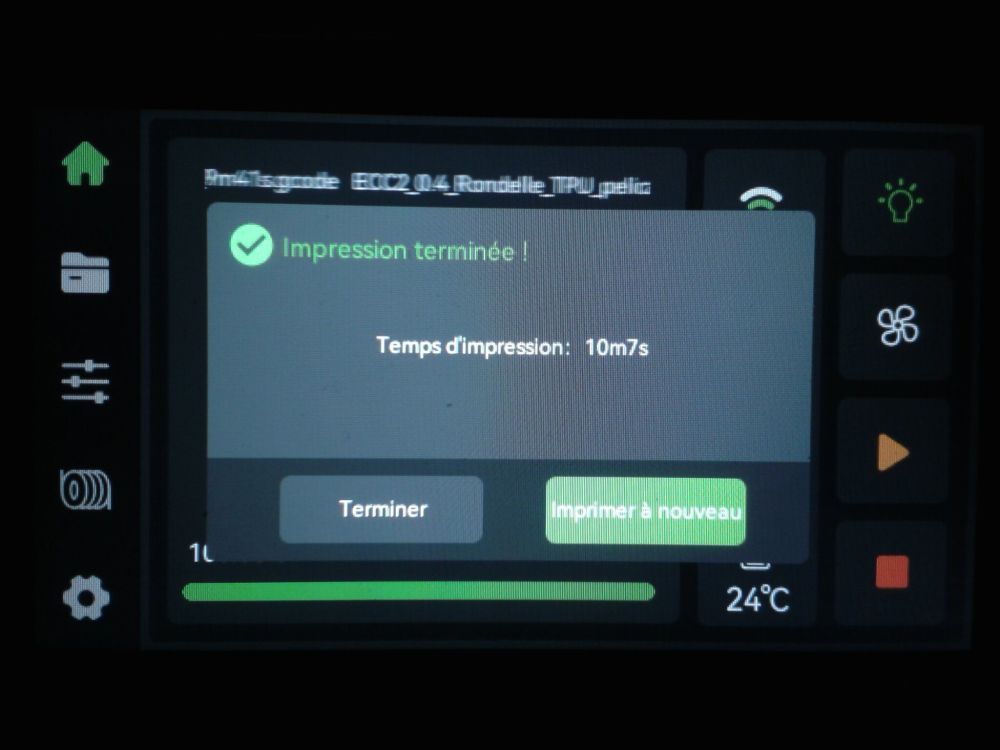


























 1 point
1 point